我发现Flink CDC2.4版本cdc连接pgsql的时候source的并行度大于1的时候会有问题。每个并行的source都会去执行创建复制槽的命令,但是目前应该是只能指定一个复制槽名称,所以后面就会报复制槽已存在的错误?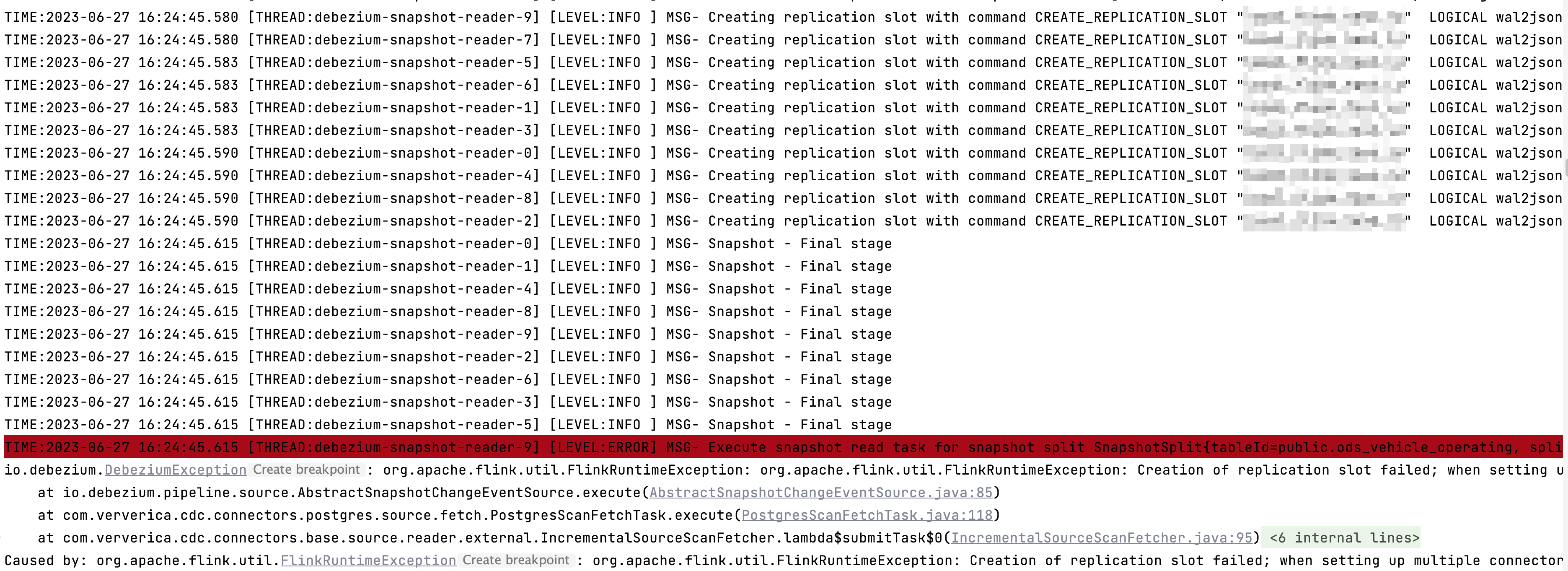
我发现Flink CDC2.4版本cdc连接pgsql的时候source的并行度大于1的时候会有问?[阿里云实时计算 Flink版]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
![]()
我发现Flink CDC2.4版本cdc连接pgsql的时候source的并行度大于1的时候会有问题。每个并行的source都会去执行创建复制槽的命令,但是目前应该是只能指定一个复制槽名称,所以后面就会报复制槽已存在的错误?
在 Flink CDC 2.4 版本中,当使用并行度大于1的 Source 连接到 PostgreSQL 数据库时,每个并行的 Source 都会尝试执行创建复制槽的命令。然而,目前 PostgreSQL 只允许指定一个复制槽名称,因此会导致后续的 Source 报告复制槽已存在的错误。
这是一个已知的问题,并且在 Flink CDC 2.5 版本中进行了修复。在新版本中,Flink CDC 引入了更好的并行度支持,并解决了该问题。更新到 Flink CDC 2.5 版本或更高版本,应该可以避免这个问题。
如果您无法立即升级到 Flink CDC 2.5 版本或更高版本,有两种临时解决方法来避免该问题:
1. 将 Source 的并行度设置为1:通过将 Source 的并行度设置为1,只启动一个 Source 实例,从而避免了多个实例同时执行创建复制槽的命令。虽然这样可能会限制并行处理能力,但可以暂时避免复制槽冲突的错误。
2. 使用自定义的复制槽名称:为每个 Source 实例指定不同的复制槽名称,以防止冲突。您可以在 PostgreSQL 中手动创建多个复制槽,并在每个 Source 的连接参数中设置不同的复制槽名称。
需要注意的是,以上两种方法都只是临时解决方案,最佳做法是升级到 Flink CDC 2.5 版本或更高版本,以获得更好的并行度支持和修复的问题。
使用 Flink CDC 2.4 版本连接 PostgreSQL 数据库时,如果 source 的并行度大于 1,可能会出现一些问题。这是因为 PostgreSQL 数据库的 MVCC(多版本并发控制)机制导致的,当多个 source 并行读取同一个表时,可能会读取到不同的数据版本,从而导致数据不一致的问题。
为了避免该问题,可以考虑以下几个解决方案:
将 source 的并行度设置为 1。这样可以确保只有一个 source 读取数据,避免多个 source 读取不同的数据版本的问题。但是这样会降低读取数据的速度,可能会影响任务的性能。
在读取数据时使用 Serializable Snapshot Isolation(SSI)隔离级别。可以使用 PostgreSQL 的 SET TRANSACTION ISOLATION LEVEL SERIALIZABLE 命令设置隔离级别,例如:
sql
Copy
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
这样可以确保在读取数据时使用 SSI 隔离级别,从而避免读取不同的数据版本的问题。但是这样会增加数据库的负载,可能会影响其他操作的性能。
在读取数据时使用锁定机制。可以使用 PostgreSQL 的 SELECT … FOR UPDATE 命令对数据进行锁定,例如:
sql
Copy
SELECT * FROM my_table WHERE id = 1 FOR UPDATE;
这样可以确保在读取数据时对数据进行锁定,避免多个 source 读取不同的数据版本的问题。但是这样会增加数据库的负载,可能会影响其他操作的性能。
需要注意的是,在使用以上解决方案时,需要根据具体情况选择最合适的方案,
PG cdc 全量阶段的slot会添加 subtask id的后缀的,应该不会冲突。可以看下如下的日志打印 ,此回答整理自钉群“Flink CDC 社区”