DataWorks中从HDFS同步数据到MaxCompute,hdfs中数据是parquet格式,列式存储,字段分隔符需要写么?这里是字段映射,任务执行报错是什么原因呢?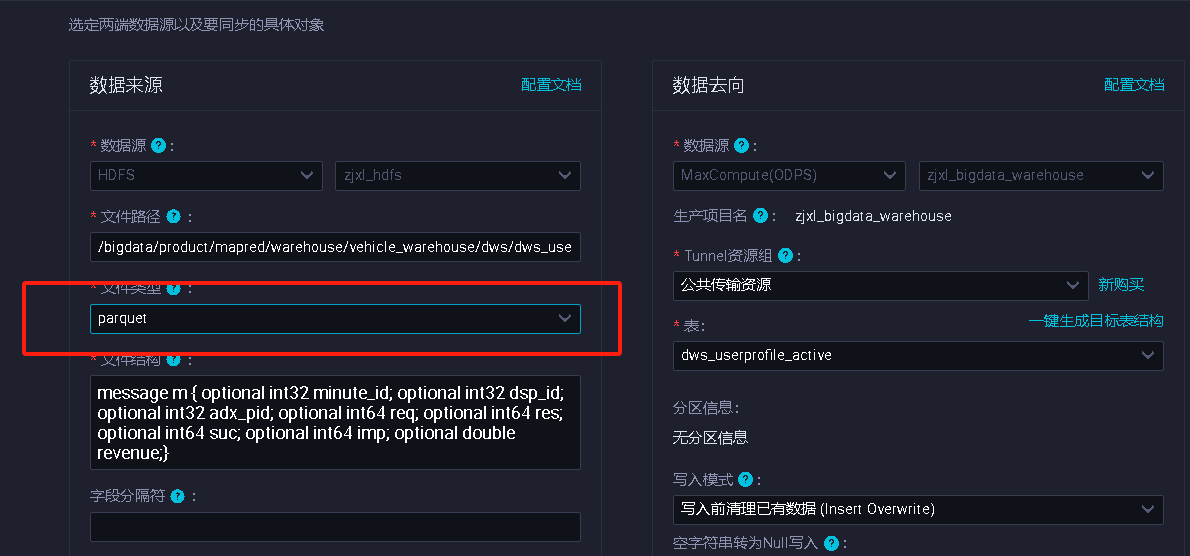

DataWorks中从HDFS同步数据到MaxCompute,字段分隔符需要写么?[阿里云MaxCompute]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
![]()
DataWorks中从HDFS同步数据到MaxCompute,hdfs中数据是parquet格式,列式存储,字段分隔符需要写么?这里是字段映射,任务执行报错是什么原因呢?
您参考看下这个配置参数
https://help.aliyun.com/zh/dataworks/user-guide/hdfs-data-source?spm=a2c4g.11186623.0.i0#task-2313264,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在阿里云的DataWorks中,从HDFS同步数据到MaxCompute时,如果源数据的格式是Parquet,那么字段分隔符是不需要的,因为Parquet是一种列式存储的格式,每个字段都有自己的压缩块,不需要通过分隔符来分割字段。
如果你的任务执行报错,可能有以下几种原因:
数据问题:可能是源数据的问题,比如数据不存在、数据格式错误等。
配置问题:可能是同步任务的配置有问题,比如目标表的定义不正确、字段映射不正确等。
权限问题:可能是MaxCompute账号的权限问题,比如没有写入目标表的权限。
网络问题:可能是网络问题,比如网络不稳定导致任务执行失败。
你可以先检查一下源数据是否存在、数据格式是否正确,然后检查一下同步任务的配置是否正确,最后检查一下MaxCompute账号的权限和网络状态。
根据你提供的信息,你正在使用DataWorks从HDFS同步数据到MaxCompute,但是遇到了一些问题。以下是一些常见的原因: