大数据计算MaxCompute我由张表有24列,每列对应一个运行数据,字段见T1、T2…..T24。
每个小时,我会接到一批数据,数据可能会是T1、T2…..T24中随机一批谁。
有什么更高效的方式将数据维护到各列中去不?数据量没有行专列之前是千万级的,转之后是百万级的?DI从接到ODPS的接口表,数据格式是:设备ID、小时、运行数据。如:需要转成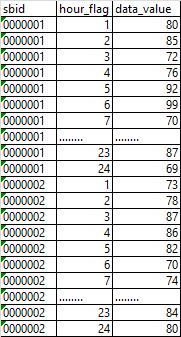

来一批更新一批
大数据计算MaxCompute有什么更高效的方式将数据维护到各列中去不?[阿里云MaxCompute]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
如果你想要将数据维护到各列中去,你可以使用MaxCompute的流式计算功能。流式计算可以让你实时地处理数据,而不需要等到数据全部到达后才能处理。这样可以提高数据处理的效率和准确性。
以下是一些使用流式计算处理数据的方法:
根据您提供的信息,您可以考虑使用MaxCompute的数据分区功能来提高数据处理的效率。数据分区可以帮助您将大型表分割成多个小表,从而加快查询速度和降低存储成本。此外,您还可以考虑使用MaxCompute的并行处理能力来提高数据处理的速度。MaxCompute支持并行处理,您可以将查询和数据处理任务分解成多个子任务,并在多个计算节点上并行执行,从而大大提高数据处理的效率。
同步速率慢? 还是在MaxCompute 更新速度慢,整体的SQL太长了。不要超过128k这是机器限制。,此回答整理自钉群“MaxCompute开发者社区2群”
在MaxCompute中,将数据维护到各列中去的高效方式是使用
INSERT INTO ... SELECT语句。您可以根据需要选择插入所有列或部分列的数据。以下是一个示例:odps_interface_table,包含设备ID、小时和运行数据字段。target_table有24个列,分别对应T1、T2…T24。您可以使用以下SQL语句将数据插入到目标表中:
如果您只需要插入部分列的数据,可以相应地调整目标表列名和查询结果中的列名。例如,如果您只需要插入T1、T3、T5和T7列的数据,可以使用以下SQL语句:
这样,您就可以根据需要将数据高效地维护到目标表的各个列中。