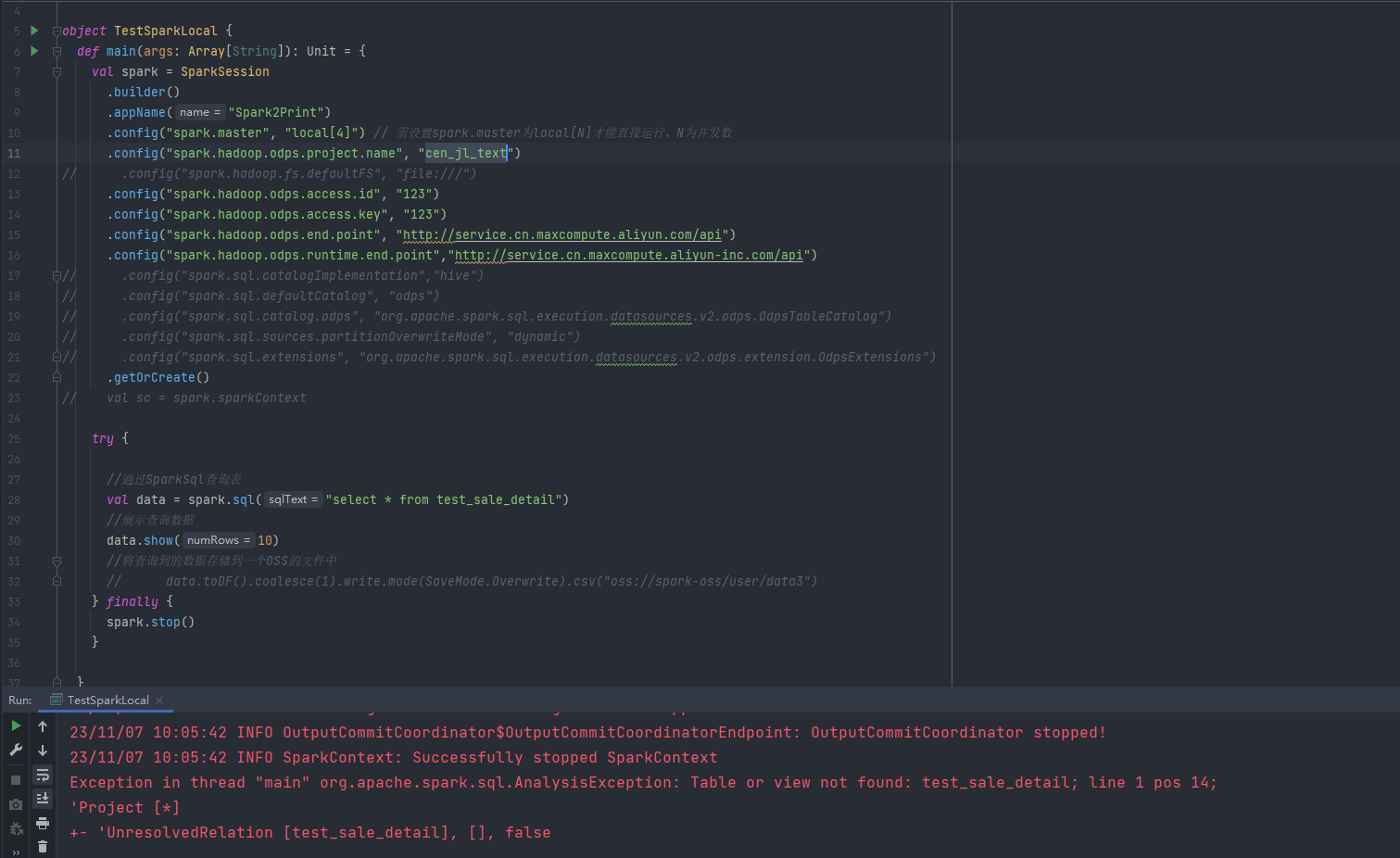
tongchenkeji 发表于:2023-11-12 6:57:160次点击 已关注取消关注 关注 私信 请问大数据计算MaxCompute spark引擎为什么读不到maxcompute上面的表呢?[阿里云MaxCompute] 暂停朗读为您朗读 请问大数据计算MaxCompute spark引擎为什么读不到maxcompute上面的表呢?是我漏配置了什么参数么? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 MaxCompute# MaxCompute2748# Spark97# 云原生大数据计算服务 MaxCompute3255# 分布式计算2827# 大数据1264
sun20AM 2023-11-27 18:33:48 2 如果大数据计算的MaxCompute Spark引擎无法读取到表,可能的原因包括: 项目名称或表名称错误:请确保您在代码中指定的项目名称和表名称与实际的项目名称和表名称一致。 访问权限问题:请检查您的账号和密码是否具有访问该表的权限。对于子用户,还需要确认子用户的权限设置是否正确。 数据格式问题:需要保证您的数据格式是MaxCompute所支持的。例如,如果您的数据是CSV格式的,那么需要将分隔符设置为逗号(或其他MaxCompute所支持的分隔符)。 网络连接问题:请确保您的网络连接正常,并且能够访问到MaxCompute服务。 参数配置问题:当使用Spark对接MaxCompute时,需要正确配置相关参数。例如,需要正确配置项目名称、表名称、访问密钥等信息。同时,对于Spark-2.x版本,需要在pom.xml文件中添加相应的依赖。 分区列名写法错误:如果是对分区表进行读写操作,需要注意分区列名=分区名的写法规范,多个分区时以逗号(,)分隔。
算精通AM 2023-11-27 18:33:48 3 创建 Spark 查询时,没有正确指定表名或者表名拼写错误导致的。请检查您的查询代码,确保表名正确且已经被识别。以下是一个使用 Spark SQL 查询 MaxCompute 表的示例: import org.apache.spark.sql.SparkSession;import org.apache.spark.sql.types.DataTypes;import org.apache.spark.sql.types.StructField;import org.apache.spark.sql.types.StructType;public class MaxComputeSparkDemo { public static void main(String[] args) { // 创建 SparkSession SparkSession spark = SparkSession.builder() .appName(“MaxCompute Spark Demo”) .master(“local[*]”) .getOrCreate(); // 读取 MaxCompute 表 String tableName = “test_sale_detail”; StructType schema = DataTypes.createStructType(new StructField[]{ DataTypes.createStructField(“id”, DataTypes.IntegerType, false), DataTypes.createStructField(“product_id”, DataTypes.IntegerType, false), DataTypes.createStructField(“sale_date”, DataTypes.DateType, false) }); Dataset dataFrame = spark.read() .format(“org.apache.hadoop.hive.ql.io.parquet.ParquetFileFormat”) .load(“maxcompute://” + tableName); // 显示数据 dataFrame.show(); // 关闭 SparkSession spark.stop(); }}CopyCopy 请确保表名(test_sale_detail)与您在 MaxCompute 上创建的表名一致,并检查您的项目依赖是否正确添加了 MaxCompute 的 JAR 文件。如果您使用的是 Maven,可以在 pom.xml 文件中添加以下依赖: com.aliyun.odps maxcompute-client 1.0.0 CopyCopy 如果您使用的是 Gradle,可以在 build.gradle 文件中添加以下依
,此回答整理自钉群“MaxCompute开发者社区2群”
如果大数据计算的MaxCompute Spark引擎无法读取到表,可能的原因包括:
项目名称或表名称错误:请确保您在代码中指定的项目名称和表名称与实际的项目名称和表名称一致。
访问权限问题:请检查您的账号和密码是否具有访问该表的权限。对于子用户,还需要确认子用户的权限设置是否正确。
数据格式问题:需要保证您的数据格式是MaxCompute所支持的。例如,如果您的数据是CSV格式的,那么需要将分隔符设置为逗号(或其他MaxCompute所支持的分隔符)。
网络连接问题:请确保您的网络连接正常,并且能够访问到MaxCompute服务。
参数配置问题:当使用Spark对接MaxCompute时,需要正确配置相关参数。例如,需要正确配置项目名称、表名称、访问密钥等信息。同时,对于Spark-2.x版本,需要在pom.xml文件中添加相应的依赖。
分区列名写法错误:如果是对分区表进行读写操作,需要注意分区列名=分区名的写法规范,多个分区时以逗号(,)分隔。
创建 Spark 查询时,没有正确指定表名或者表名拼写错误导致的。请检查您的查询代码,确保表名正确且已经被识别。
以下是一个使用 Spark SQL 查询 MaxCompute 表的示例:
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class MaxComputeSparkDemo {
public static void main(String[] args) {
// 创建 SparkSession
SparkSession spark = SparkSession.builder()
.appName(“MaxCompute Spark Demo”)
.master(“local[*]”)
.getOrCreate();
// 读取 MaxCompute 表
String tableName = “test_sale_detail”;
StructType schema = DataTypes.createStructType(new StructField[]{
DataTypes.createStructField(“id”, DataTypes.IntegerType, false),
DataTypes.createStructField(“product_id”, DataTypes.IntegerType, false),
DataTypes.createStructField(“sale_date”, DataTypes.DateType, false)
});
Dataset dataFrame = spark.read()
.format(“org.apache.hadoop.hive.ql.io.parquet.ParquetFileFormat”)
.load(“maxcompute://” + tableName);
// 显示数据
dataFrame.show();
// 关闭 SparkSession
spark.stop();
}
}
CopyCopy
请确保表名(test_sale_detail)与您在 MaxCompute 上创建的表名一致,并检查您的项目依赖是否正确添加了 MaxCompute 的 JAR 文件。如果您使用的是 Maven,可以在 pom.xml 文件中添加以下依赖:
com.aliyun.odps
maxcompute-client
1.0.0
CopyCopy
如果您使用的是 Gradle,可以在 build.gradle 文件中添加以下依