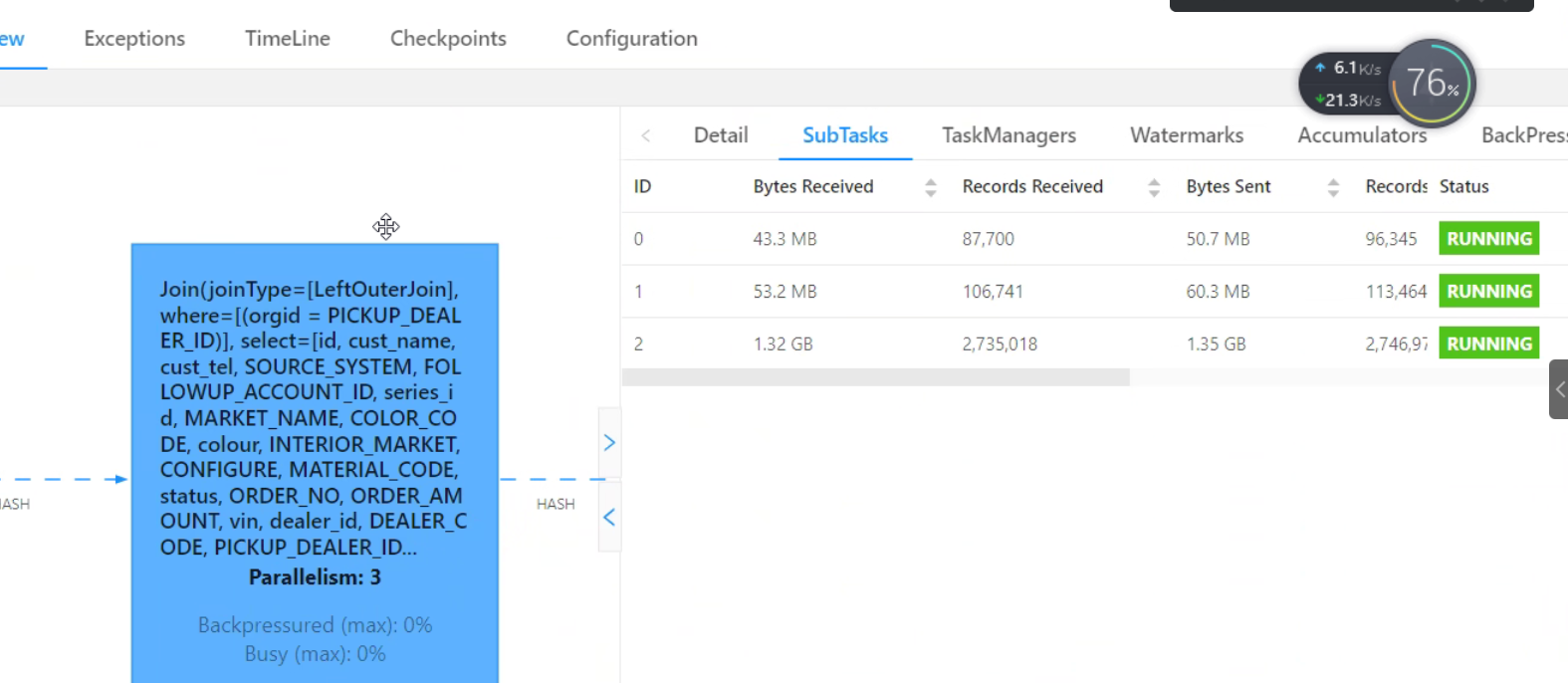
tongchenkeji 发表于:2023-2-7 15:13:130次点击 已关注取消关注 关注 私信 有朋友使用过Flink多张流表进行join产生的数据倾斜如何处理和优化的?[阿里云实时计算 Flink版] 暂停朗读为您朗读 有朋友使用过Flink多张流表进行join产生的数据倾斜如何处理和优化的?? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 实时计算Flink版# 实时计算 Flink版3179# 流计算2236
认真学习的heartAM 2023-11-27 18:35:22 1 我想到四个方法,你可以去试一下 将数据进行重分区,使用HashPartitioner或者RangePartitioner。 使用Flink的Rebalance算子,将数据重新分发到不同的TaskManager上 使用Flink的CoGroup算子,将多张流表进行join操作 使用Flink的MapPartition算子,将多张流表进行join操作
665661AM 2023-11-27 18:35:22 2 flink有个重分区的算子,不过你先调研一下是哪些数据发生数据倾斜呀——该回答整理自钉群“【③群】Apache Flink China社区”
我想到四个方法,你可以去试一下
将数据进行重分区,使用HashPartitioner或者RangePartitioner。
使用Flink的Rebalance算子,将数据重新分发到不同的TaskManager上
使用Flink的CoGroup算子,将多张流表进行join操作
使用Flink的MapPartition算子,将多张流表进行join操作
flink有个重分区的算子,不过你先调研一下是哪些数据发生数据倾斜呀——该回答整理自钉群“【③群】Apache Flink China社区”