代码实现mongo数据整库写hudi,采用RocksDBStateBackend状态后端,在Flink中checkpoint产生的文件名太长报错,各位大佬有遇到的吗?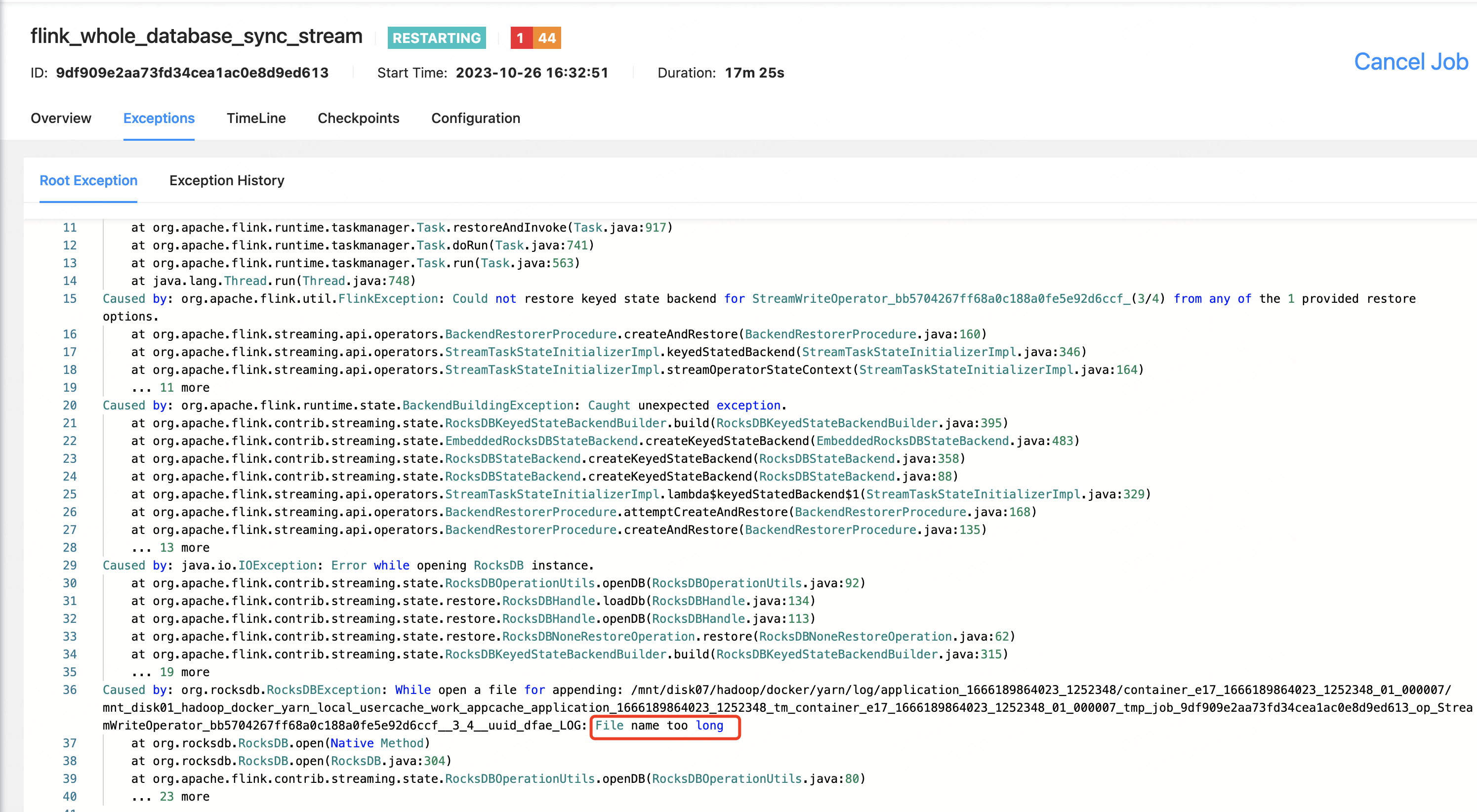
在Flink中checkpoint产生的文件名太长报错,各位大佬有遇到的吗?[阿里云实时计算 Flink版]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
![]()
代码实现mongo数据整库写hudi,采用RocksDBStateBackend状态后端,在Flink中checkpoint产生的文件名太长报错,各位大佬有遇到的吗?
确实有遇到这种情况的可能。当使用Flink的RocksDBStateBackend时,由于RocksDB的特性,可能会在磁盘上生成大量的文件。特别是在使用checkpoint的时候,可能会产生大量的文件。如果文件名过长,可能会超过操作系统允许的文件名长度限制,从而产生错误。
这个问题可以通过以下几种方式解决:
state.backend.rocksdb.local-db-dirs的数量,让数据分布在更多的目录中。在使用 RocksDBStateBackend 过程中,确实可能会遇到 checkpoint 文件名过长而导致的错误。由于 Linux 系统限制了文件路径的最大长度为 255 字节,当 checkpoint 文件名称太长时就会发生错误。
解决这个问题的方法有两种:
当采用 RocksDBStateBackend 作为状态后端时,在 Flink 中可能出现文件名过长的问题,请采取如下措施:
*.json或*.txt等;调整一下rocksdbjni包的版本。此回答整理自钉群“【②群】Apache Flink China社区”