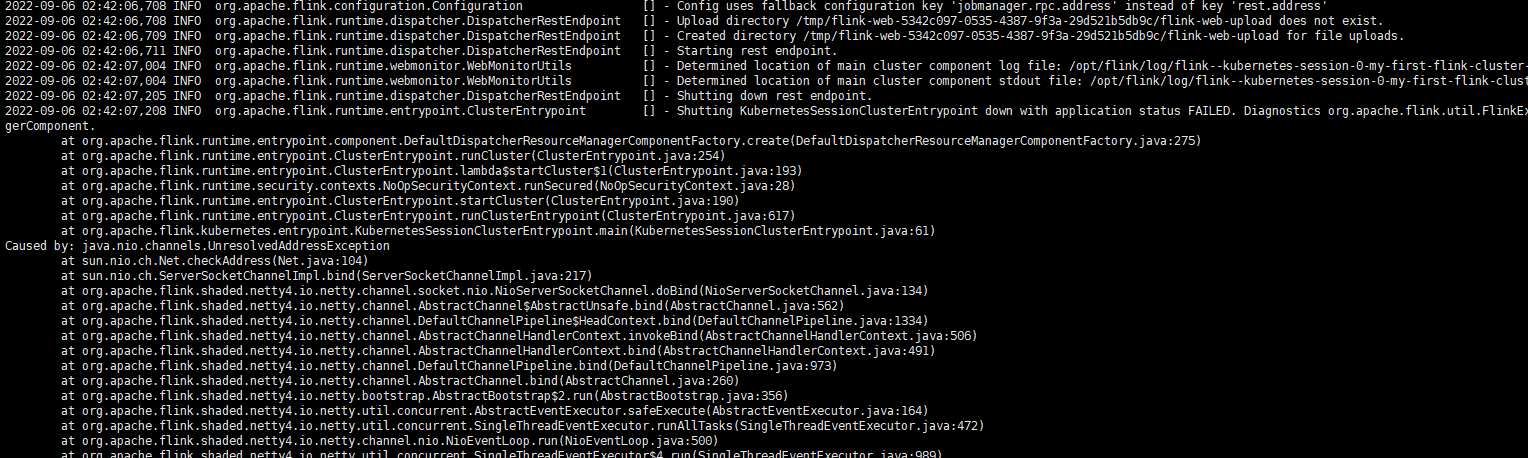
tongchenkeji 发表于:2022-9-7 14:07:330次点击 已关注取消关注 关注 私信 有大佬做native flink on k8s的部署方案吗,按照官网的配置,报这种异常,大佬帮忙瞅瞅[阿里云实时计算 Flink版] 暂停朗读为您朗读 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 实时计算Flink版# Kubernetes381# 实时计算 Flink版3179# 容器895# 容器服务Kubernetes版597# 流计算2236
wljslmzAM 2023-11-27 18:38:47 1 Flink on Kubernetes 的部署和调试可能会比较复杂,需要多方面考虑以确保集群的正确部署。下面提供一些常见问题的解决方案,希望可以帮助到您: 检查 Kubernetes 集群配置 首先,您需要检查 Kubernetes 集群的配置信息,确保您提供的配置信息正确。在阿里云上搭建 Kubernetes 集群可能需要特殊的网络配置和存储配置。您可以参考阿里云 Kubernetes 官方文档:https://help.aliyun.com/product/30520.html 进行设置。 查看 Flink on Kubernetes 输出日志 您可以尝试查看 Flink on Kubernetes 的输出日志,看看是否有相关的错误信息。在部署 Flink 应用程序时,可以使用以下命令查看 Kubernetes Pod 中 Flink 的日志: # 查看 TaskManager 的日志kubectl logs -f -c taskmanager# 查看 JobManager 的日志kubectl logs -f -c jobmanager 在查看 Flink 日志时,您需要关注以下信息: Flink 应用程序在启动时是否成功。 Flink 应用程序中运行的作业是否启动成功。 Flink 应用程序中的输入和输出是否被正确地设置和连接。 如果存在任何问题,日志文件中可能会有相关的错误信息和异常信息。 检查 Flink 应用程序的配置 在部署 Flink 应用程序时,需要提供一些配置信息以确保应用程序能够正确地启动。您可以检查以下配置信息以解决问题: 作业的并行度是否正确。 是否正确配置了输入和输出连接器。 是否正确配置了资源限制、容器日志、容器网络等相关信息。 如果您提供的配置信息存在问题,可能导致 Flink 应用程序启动失败或无法正常工作。 检查 Flink on Kubernetes 版本的兼容性 Flink on Kubernetes 的部署需要考虑 Flink 和 Kubernetes 的版本兼容性。在选择使用的 Flink 和 Kubernetes 版本时,您可以参考 Flink on Kubernetes 官方文档:https://ci.apache.org/projects/flink/flink-docs-stable/deployment/resource-providers/kubernetes.html#prerequisites-and-compatibility 进行设置。
六月的雨在钉钉AM 2023-11-27 18:38:47 2 根据错误提示Caused by: java.nio.channels.UnresolvedAddressException来看的话应该是域名映射没有配置或者没有配全,配置host进行IP地址与Host域名映射配置。
穿过生命散发芬芳AM 2023-11-27 18:38:47 3 java.nio.channels.UnresolvedAddressException 异常通常是由于 Flink 的 TaskManager 无法解析 Kubernetes Pod 的地址导致的。 此问题可能是由于您的 Kubernetes 集群中缺少 DNS 解析服务或 Pod 网络配置不正确造成的。请确保您的 Pod 网络配置正确,Probe 检查成功,并且能够从容器中解析出外部服务的 DNS 名称。 以下是一些可能导致此问题的情况和解决方法: 1、检查 Pod 网络配置是否正确。可以使用以下命令检查是否能够 Ping 通 Pod 和 Service 的 IP 地址: kubectl exec -it {client-pod-name} -- ping {pod-ip-address} -c 3kubectl exec -it {client-pod-name} -- ping {service-ip-address} -c 3 如果无法 Ping 通,则说明您的 Pod 网络配置可能有问题,请根据具体情况进行排查。 2、检查您的 Kubernetes 集群是否可以进行 DNS 解析。可以在 Kubernetes 集群中的 Pod 中使用 nslookup 命令检查外部服务的 DNS 是否能够被正确解析: kubectl exec -it {client-pod-name} -- nslookup {service-name} 如果无法解析,则可能是您的 Kubernetes 集群中缺少 DNS 解析服务,请根据具体情况进行排查。 3、检查您的 Kubernetes 集群中是否启用了 CoreDNS。默认情况下,Kubernetes 1.13 及更高版本中会使用 CoreDNS 作为默认的 DNS 解析服务。请确保您的 Kubernetes 集群中已启用 CoreDNS,并且其版本符合 Flink 所支持的版本要求。 如果您的 Kubernetes 集群中已经使用了 CoreDNS,但仍然无法解决 java.nio.channels.UnresolvedAddressException 异常,请在 Flink TaskManager 的 Pod 中添加额外的 DNS 配置,并将其指向运行 CoreDNS 的 Pod。以下是一种可能的解决方法: 1、编写 CoreDNS 配置文件,例如: apiVersion: v1kind: ConfigMapmetadata: name: coredns-serverdata: Corefile: | .:53 { forward . {{ .Values.dns.upstream }} log errors } 其中 .Values.dns.upstream 可以指向运行 CoreDNS 的 Pod 的 IP 地址和端口(例如 10.1.2.3:53),也可以使用 ConfigMap 定义 DNS 服务地址。 2、将 CoreDNS 的配置文件挂载到 Flink TaskManager 的 Pod: apiVersion: apps/v1kind: Deploymentmetadata: name: flink-taskmanager labels: app.kubernetes.io/name: flink app.kubernetes.io/component: taskmanagerspec: replicas: 2 template: metadata: labels: app.kubernetes.io/name: flink app.kubernetes.io/component: taskmanager spec: volumes: - name: coredns-config configMap: name: coredns-server # 引用上文定义的 ConfigMap containers: - name: taskmanager image: apache/flink:1.14.2-scala_2.12 command: ["/bin/bash", "/opt/flink/bin/start-taskmanager.sh"] args: ["foreground"] env: - name: FLINK_TASK_MANAGER_HEAP_SIZE value: "512m" volumeMounts: - name: coredns-config mountPath: /etc/coredns 在以上示例中,我们为 Flink TaskManager 的 Pod 添加了名为 coredns-config 的数据卷,并将其挂载到了容器的 /etc/coredns 目录中,以便让 TaskManager 可以访问
魏红斌AM 2023-11-27 18:38:47 4 针对这种情况,建议您首先检查 Flink 和 Kubernetes 集群之间的连接是否正常,例如网络配置、认证信息和 Kubernetes API 访问权限等。如果连接正常,可以进一步检查 Flink 应用程序的配置和资源分配情况,例如 TaskManager 的数量、内存和 CPU 的分配等。另外,还需要确认应用程序的代码是否存在一些潜在的错误,例如类型不匹配、空指针异常等。
ReaganYoungAM 2023-11-27 18:38:47 5 您好,关于您提到的 Flink on Kubernetes 的部署问题,我可以给出以下建议: 确认 Kubernetes 集群中 DNS 的配置是否正确。您可以通过在 Kubernetes 集群中运行 kubectl get svc -n kube-system 命令来获取 DNS 服务的 IP 地址和端口号,并确认它们是否正确。 确认 Flink on Kubernetes 的配置是否正确。您可以通过检查 Flink on Kubernetes 的配置文件或命令行参数来确认它们是否正确。例如,您可以检查 flink-conf.yaml 文件中的 jobmanager.rpc.address 和 jobmanager.rpc.port 参数是否正确设置。 检查 Flink on Kubernetes 的日志,查看是否有其他错误或异常信息。您可以通过运行 kubectl logs -f 命令来获取 Flink on Kubernetes 的日志信息。 确认 Flink on Kubernetes 的镜像是否正确。您可以通过运行 kubectl describe pod 命令来查看 Flink on Kubernetes 的容器的状态和事件,确认是否成功拉取镜像及容器是否正常运行。 如果以上建议无法解决您的问题,您可以提供更多的详细信息,例如 Flink on Kubernetes 部署的具体方式、版本信息、错误日志等,以便我们更好地帮助您解决问题。
爱吃白菜的GGBAM 2023-11-27 18:38:47 6 这个异常是由于 Flink JobManager 绑定到了无效的 IP 地址或主机名导致的。你需要检查你的 Flink JobManager 配置,确保它使用的是有效的 IP 地址或主机名。 如果你使用的是 Kubernetes 集群,在 Flink JobManager 的 YAML 配置文件中,可以尝试将 jobmanager.rpc.address 设置为 Kubernetes Service 的 IP 地址或主机名,例如: apiVersion: apps/v1kind: Deploymentmetadata: name: flink-jobmanagerspec: replicas: 1 selector: matchLabels: app: flink component: jobmanager template: metadata: labels: app: flink component: jobmanager spec: containers: - name: jobmanager image: flink:1.13.2-scala_2.12 env: - name: JOB_MANAGER_RPC_ADDRESS value: flink-jobmanager ports: - containerPort: 6123 在这个例子中,JOB_MANAGER_RPC_ADDRESS 被设置为 flink-jobmanager,这是 Kubernetes Service 的名称。如果你的 Kubernetes Service 使用了不同的名称,需要相应地修改。 另外,你还可以检查 Flink 集群的配置文件,例如 flink-conf.yaml,确保其中的 jobmanager.rpc.address 也设置为有效的 IP 地址或主机名。 希望这些信息能够帮助你解决问题。如果问题仍然存在,请提供更多详细信息,以便我们更好地帮助你。
三掌柜666AM 2023-11-27 18:38:47 7 楼主你好,根据你的报错提示可以看到,大概率是因为Flink的JobManager在容器中无法检查自身的名称和连接IP地址造成的报错,你可以尝试修改JobManager的配置,让它可以正常获取信息。
叶秋学长AM 2023-11-27 18:38:47 8 根据错误信息,看起来是 Kubernetes 的 DNS 配置出现了问题。可能是由于 DNS 管理器(例如 CoreDNS)未正确部署或未正常运行导致的。 您可以尝试使用 kubectl 命令检查 CoreDNS 状态,如下所示: Copy code kubectl get pods -n kube-system -l k8s-app=kube-dns 确保所有的 CoreDNS Pod 的状态都是 Running。 如果 CoreDNS 正在运行,请尝试重新启动 Flink 集群以确保它们具有正确的 DNS 配置。如果问题仍然存在,请检查 Kubernetes DNS 配置是否正确。
祁符建AM 2023-11-27 18:38:47 9 首先,您的异常信息缺失了一部分内容,无法判断具体问题。建议您提供完整的异常信息。 其次,Flink On Kubernetes 部署方案需要结合 Kubernetes 的特性进行调整和配置。建议您查看 Flink 官网中关于在 Kubernetes 上运行 Flink 的官方文档,按照文档中的指导进行操作。 如果您仍然遇到问题,请详细描述您的环境信息、部署过程和具体异常信息,以方便更好地帮助您解决问题。 在部署 Native Flink on Kubernetes 的过程中可能会出现各种异常,这些异常可能来自于以下几个方面: 配置问题:Flink on Kubernetes 的配置需要结合 Kubernetes 的特性进行调整和配置,如果在配置过程中存在错误,就可能导致异常的发生。 环境问题:Kubernetes 环境可能存在网络、存储等问题,这些问题也有可能导致 Flink on Kubernetes 的异常。 资源问题:Flink on Kubernetes 需要运行在 Kubernetes 集群中,如果 Kubernetes 集群的资源(CPU、内存等)不足或者分配不当,也可能引起 Flink on Kubernetes 的异常。 应用问题:Flink 应用本身可能存在代码错误或者逻辑问题,这些问题同样有可能导致 Flink on Kubernetes 的异常。 对于具体的异常问题,需要根据异常信息进行分析和排查,通常可以通过查看日志、监控指标等方式找到问题所在。同时,建议使用最新版本的 Flink 和 Kubernetes,在部署过程中按照官方文档进行操作,避免一些已知的问题。
vohelonAM 2023-11-27 18:38:47 10 根据你提供的截图,可能是由于 Flink JobManager 在容器中无法通过 Kubernetes API 检查自身的 Pod 名称和 IP 地址导致的。解决方案是修改 JobManager 的配置,让它可以通过 Kubernetes 的 API 来获取 Pod 的信息。 具体的做法是在 Flink 的配置文件中增加以下配置项: kubernetes.cluster-id: kubernetes.jobmanager-service-account: 其中 是 Kubernetes 集群的 ID,可以通过命令 kubectl config current-context 来获取; 是用于访问 Kubernetes API 的 Service Account 名称,在 Flink 集群部署时需要先创建并授权。 如果你已经设置了这些配置项,但仍然出现类似的异常,可能是 Kubernetes API 的访问权限不足,需要进行进一步的授权设置。
武当张三丰丶AM 2023-11-27 18:38:47 11 这个错误可能是由于在Flink作业中使用了不正确的资源组件导致的。请确保正在使用正确的资源组件,并且已正确配置了Flink作业。检查Flink版本和资源组件版本,并确保它们都是最新的。也可以尝试在Flink官方文档中查找有关资源组件的更多信息。
Flink on Kubernetes 的部署和调试可能会比较复杂,需要多方面考虑以确保集群的正确部署。下面提供一些常见问题的解决方案,希望可以帮助到您:
首先,您需要检查 Kubernetes 集群的配置信息,确保您提供的配置信息正确。在阿里云上搭建 Kubernetes 集群可能需要特殊的网络配置和存储配置。您可以参考阿里云 Kubernetes 官方文档:https://help.aliyun.com/product/30520.html 进行设置。
您可以尝试查看 Flink on Kubernetes 的输出日志,看看是否有相关的错误信息。在部署 Flink 应用程序时,可以使用以下命令查看 Kubernetes Pod 中 Flink 的日志:
在查看 Flink 日志时,您需要关注以下信息:
如果存在任何问题,日志文件中可能会有相关的错误信息和异常信息。
在部署 Flink 应用程序时,需要提供一些配置信息以确保应用程序能够正确地启动。您可以检查以下配置信息以解决问题:
如果您提供的配置信息存在问题,可能导致 Flink 应用程序启动失败或无法正常工作。
Flink on Kubernetes 的部署需要考虑 Flink 和 Kubernetes 的版本兼容性。在选择使用的 Flink 和 Kubernetes 版本时,您可以参考 Flink on Kubernetes 官方文档:https://ci.apache.org/projects/flink/flink-docs-stable/deployment/resource-providers/kubernetes.html#prerequisites-and-compatibility 进行设置。
根据错误提示Caused by: java.nio.channels.UnresolvedAddressException来看的话应该是域名映射没有配置或者没有配全,配置host进行IP地址与Host域名映射配置。
java.nio.channels.UnresolvedAddressException 异常通常是由于 Flink 的 TaskManager 无法解析 Kubernetes Pod 的地址导致的。
此问题可能是由于您的 Kubernetes 集群中缺少 DNS 解析服务或 Pod 网络配置不正确造成的。请确保您的 Pod 网络配置正确,Probe 检查成功,并且能够从容器中解析出外部服务的 DNS 名称。
以下是一些可能导致此问题的情况和解决方法: 1、检查 Pod 网络配置是否正确。可以使用以下命令检查是否能够 Ping 通 Pod 和 Service 的 IP 地址:
kubectl exec -it {client-pod-name} -- ping {pod-ip-address} -c 3kubectl exec -it {client-pod-name} -- ping {service-ip-address} -c 3如果无法 Ping 通,则说明您的 Pod 网络配置可能有问题,请根据具体情况进行排查。
2、检查您的 Kubernetes 集群是否可以进行 DNS 解析。可以在 Kubernetes 集群中的 Pod 中使用 nslookup 命令检查外部服务的 DNS 是否能够被正确解析:
kubectl exec -it {client-pod-name} -- nslookup {service-name}如果无法解析,则可能是您的 Kubernetes 集群中缺少 DNS 解析服务,请根据具体情况进行排查。
3、检查您的 Kubernetes 集群中是否启用了 CoreDNS。默认情况下,Kubernetes 1.13 及更高版本中会使用 CoreDNS 作为默认的 DNS 解析服务。请确保您的 Kubernetes 集群中已启用 CoreDNS,并且其版本符合 Flink 所支持的版本要求。
如果您的 Kubernetes 集群中已经使用了 CoreDNS,但仍然无法解决 java.nio.channels.UnresolvedAddressException 异常,请在 Flink TaskManager 的 Pod 中添加额外的 DNS 配置,并将其指向运行 CoreDNS 的 Pod。以下是一种可能的解决方法:
1、编写 CoreDNS 配置文件,例如:
apiVersion: v1kind: ConfigMapmetadata: name: coredns-serverdata: Corefile: | .:53 { forward . {{ .Values.dns.upstream }} log errors }其中 .Values.dns.upstream 可以指向运行 CoreDNS 的 Pod 的 IP 地址和端口(例如 10.1.2.3:53),也可以使用 ConfigMap 定义 DNS 服务地址。
2、将 CoreDNS 的配置文件挂载到 Flink TaskManager 的 Pod:
在以上示例中,我们为 Flink TaskManager 的 Pod 添加了名为 coredns-config 的数据卷,并将其挂载到了容器的 /etc/coredns 目录中,以便让 TaskManager 可以访问
针对这种情况,建议您首先检查 Flink 和 Kubernetes 集群之间的连接是否正常,例如网络配置、认证信息和 Kubernetes API 访问权限等。如果连接正常,可以进一步检查 Flink 应用程序的配置和资源分配情况,例如 TaskManager 的数量、内存和 CPU 的分配等。另外,还需要确认应用程序的代码是否存在一些潜在的错误,例如类型不匹配、空指针异常等。
您好,关于您提到的 Flink on Kubernetes 的部署问题,我可以给出以下建议:
确认 Kubernetes 集群中 DNS 的配置是否正确。您可以通过在 Kubernetes 集群中运行 kubectl get svc -n kube-system 命令来获取 DNS 服务的 IP 地址和端口号,并确认它们是否正确。
确认 Flink on Kubernetes 的配置是否正确。您可以通过检查 Flink on Kubernetes 的配置文件或命令行参数来确认它们是否正确。例如,您可以检查 flink-conf.yaml 文件中的 jobmanager.rpc.address 和 jobmanager.rpc.port 参数是否正确设置。
检查 Flink on Kubernetes 的日志,查看是否有其他错误或异常信息。您可以通过运行 kubectl logs -f 命令来获取 Flink on Kubernetes 的日志信息。
确认 Flink on Kubernetes 的镜像是否正确。您可以通过运行 kubectl describe pod 命令来查看 Flink on Kubernetes 的容器的状态和事件,确认是否成功拉取镜像及容器是否正常运行。
如果以上建议无法解决您的问题,您可以提供更多的详细信息,例如 Flink on Kubernetes 部署的具体方式、版本信息、错误日志等,以便我们更好地帮助您解决问题。
这个异常是由于 Flink JobManager 绑定到了无效的 IP 地址或主机名导致的。你需要检查你的 Flink JobManager 配置,确保它使用的是有效的 IP 地址或主机名。 如果你使用的是 Kubernetes 集群,在 Flink JobManager 的 YAML 配置文件中,可以尝试将
jobmanager.rpc.address设置为 Kubernetes Service 的 IP 地址或主机名,例如:在这个例子中,
JOB_MANAGER_RPC_ADDRESS被设置为flink-jobmanager,这是 Kubernetes Service 的名称。如果你的 Kubernetes Service 使用了不同的名称,需要相应地修改。另外,你还可以检查 Flink 集群的配置文件,例如
flink-conf.yaml,确保其中的jobmanager.rpc.address也设置为有效的 IP 地址或主机名。希望这些信息能够帮助你解决问题。如果问题仍然存在,请提供更多详细信息,以便我们更好地帮助你。
楼主你好,根据你的报错提示可以看到,大概率是因为Flink的JobManager在容器中无法检查自身的名称和连接IP地址造成的报错,你可以尝试修改JobManager的配置,让它可以正常获取信息。
根据错误信息,看起来是 Kubernetes 的 DNS 配置出现了问题。可能是由于 DNS 管理器(例如 CoreDNS)未正确部署或未正常运行导致的。
您可以尝试使用 kubectl 命令检查 CoreDNS 状态,如下所示:
Copy code
确保所有的 CoreDNS Pod 的状态都是 Running。
如果 CoreDNS 正在运行,请尝试重新启动 Flink 集群以确保它们具有正确的 DNS 配置。如果问题仍然存在,请检查 Kubernetes DNS 配置是否正确。
首先,您的异常信息缺失了一部分内容,无法判断具体问题。建议您提供完整的异常信息。 其次,Flink On Kubernetes 部署方案需要结合 Kubernetes 的特性进行调整和配置。建议您查看 Flink 官网中关于在 Kubernetes 上运行 Flink 的官方文档,按照文档中的指导进行操作。 如果您仍然遇到问题,请详细描述您的环境信息、部署过程和具体异常信息,以方便更好地帮助您解决问题。
在部署 Native Flink on Kubernetes 的过程中可能会出现各种异常,这些异常可能来自于以下几个方面:
配置问题:Flink on Kubernetes 的配置需要结合 Kubernetes 的特性进行调整和配置,如果在配置过程中存在错误,就可能导致异常的发生。
环境问题:Kubernetes 环境可能存在网络、存储等问题,这些问题也有可能导致 Flink on Kubernetes 的异常。
资源问题:Flink on Kubernetes 需要运行在 Kubernetes 集群中,如果 Kubernetes 集群的资源(CPU、内存等)不足或者分配不当,也可能引起 Flink on Kubernetes 的异常。
应用问题:Flink 应用本身可能存在代码错误或者逻辑问题,这些问题同样有可能导致 Flink on Kubernetes 的异常。
对于具体的异常问题,需要根据异常信息进行分析和排查,通常可以通过查看日志、监控指标等方式找到问题所在。同时,建议使用最新版本的 Flink 和 Kubernetes,在部署过程中按照官方文档进行操作,避免一些已知的问题。
根据你提供的截图,可能是由于 Flink JobManager 在容器中无法通过 Kubernetes API 检查自身的 Pod 名称和 IP 地址导致的。解决方案是修改 JobManager 的配置,让它可以通过 Kubernetes 的 API 来获取 Pod 的信息。
具体的做法是在 Flink 的配置文件中增加以下配置项:
其中
kubectl config current-context来获取;如果你已经设置了这些配置项,但仍然出现类似的异常,可能是 Kubernetes API 的访问权限不足,需要进行进一步的授权设置。
这个错误可能是由于在Flink作业中使用了不正确的资源组件导致的。请确保正在使用正确的资源组件,并且已正确配置了Flink作业。检查Flink版本和资源组件版本,并确保它们都是最新的。也可以尝试在Flink官方文档中查找有关资源组件的更多信息。