tongchenkeji 发表于:2023-11-15 7:48:280次点击 已关注取消关注 关注 私信 DataWorks为什么在数据分析下查询出来的数据会出现覆盖情况呢?[阿里云DataWorks] 暂停朗读为您朗读 DataWorks为什么在数据分析下查询出来的数据会出现覆盖情况呢?两个表都有相同的字段会出现覆盖其中一个? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 DataWorks# DataWorks3343# 大数据开发治理平台 DataWorks3946
sun20AM 2023-11-27 21:13:29 1 DataWorks在数据分析下查询出来的数据出现覆盖情况可能有多种原因。以下是一些可能的原因: 数据源问题:如果两个表中的数据源存在重复或重叠的部分,那么在查询时可能会出现数据覆盖的情况。这可能是因为两个表使用了相同的数据源,或者其中一个表的数据源包含了另一个表的数据源。 查询条件问题:查询条件可能存在问题,导致查询结果不完整或者重复。例如,如果查询条件只过滤了一个表中的数据,而没有考虑到另一个表中的数据,就可能会出现数据覆盖的情况。 数据处理问题:在数据处理过程中,如果没有正确地处理数据,也可能会出现数据覆盖的情况。例如,如果在合并两个表的数据时,没有正确地处理重复的字段,就可能会出现数据覆盖的情况。 要解决这个问题,可以尝试以下方法: 检查数据源:检查两个表的数据源是否相同或重叠,如果存在重复或重叠的部分,可以考虑调整数据源,避免重复。 优化查询条件:重新审视查询条件,确保查询结果完整且不重复。可以考虑使用更严格的条件来过滤数据,或者使用联合查询来合并两个表的数据。 优化数据处理过程:检查数据处理过程是否存在问题,特别是在合并两个表的数据时,要确保正确地处理重复的字段。
小周sirAM 2023-11-27 21:13:29 2 在DataWorks中,如果两个表有相同字段,但在JOIN操作或聚合操作之后的结果集中,可能出现数据覆盖的情况。这种情况通常是由于JOIN或聚合操作之后结果集中字段重名引起的。由于DataWorks无法确定哪个字段对应哪个表,因此它会简单地将重复字段合并在一起,可能导致数据覆盖。为了避免这种情况发生,建议您在JOIN或聚合操作之前给每个表的字段添加别名,以确保字段名称唯一。例如: SELECT t1.field1 as field1_t1, t2.field1 as field1_t2 FROM table1 t1 JOIN table2 t2 ON t1.id = t2.id; 这样,在结果集中就不会出现字段重名的情况,也不会发生数据覆盖。另外,您还可以通过调整JOIN或聚合操作的顺序和规则,以确保数据不会发生覆盖。例如,可以优先JOIN具有较少记录的表,并尽可能保留原始字段名称,以防止字段重名。
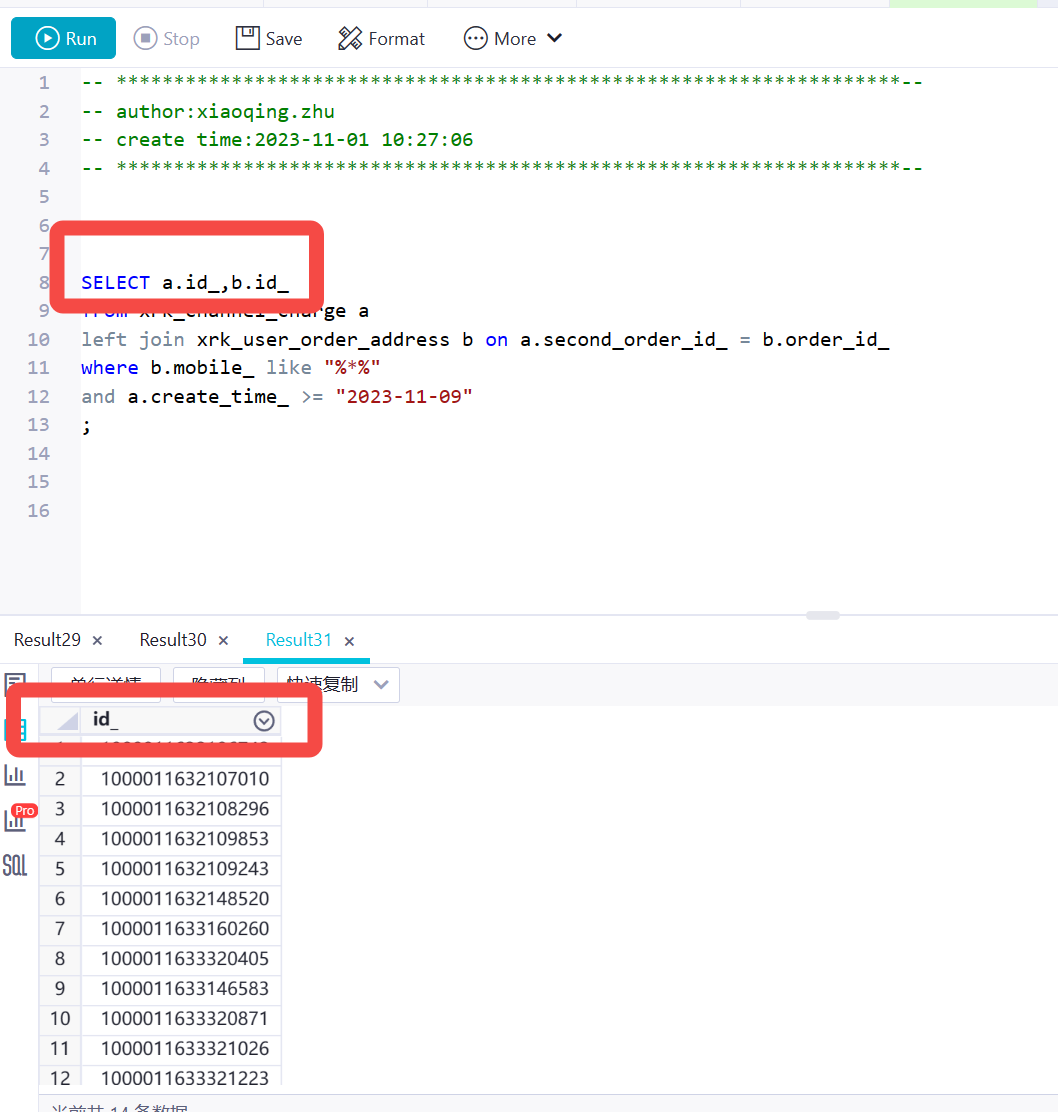
xin在这AM 2023-11-27 21:13:29 3 查询了两个字段 实际只展示了一个字段是吗 运行日志里有份logview 辛苦点开看下里面的result是几列,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
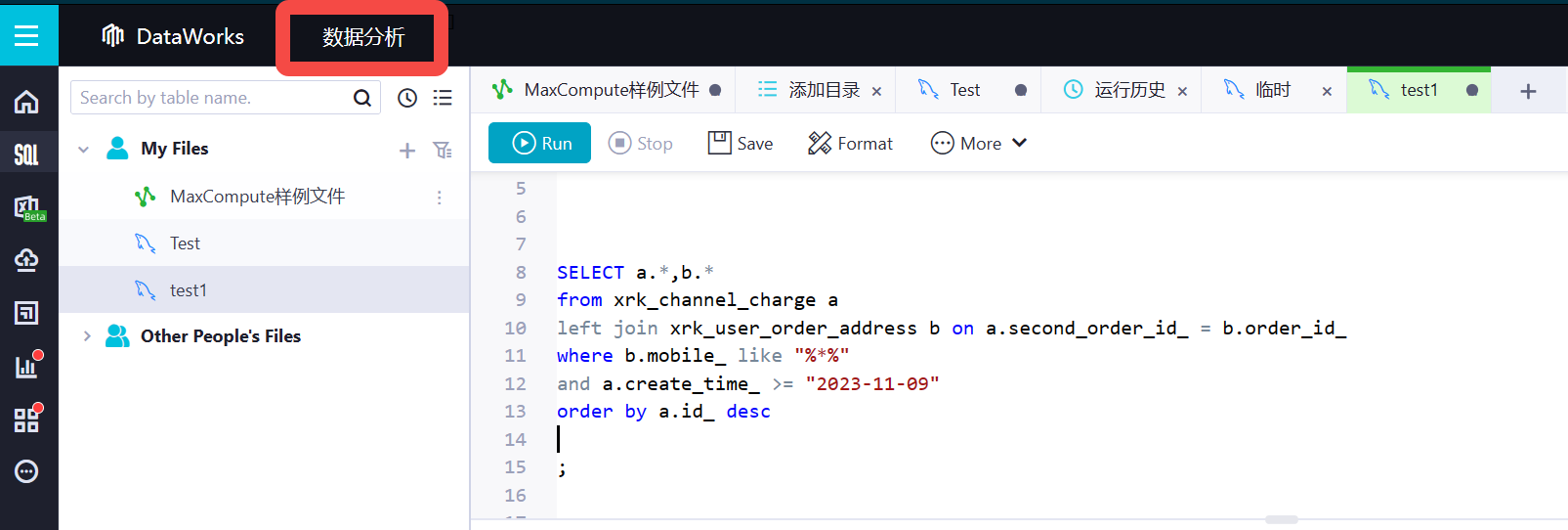
DataWorks在数据分析下查询出来的数据出现覆盖情况可能有多种原因。以下是一些可能的原因:
要解决这个问题,可以尝试以下方法:
在DataWorks中,如果两个表有相同字段,但在JOIN操作或聚合操作之后的结果集中,可能出现数据覆盖的情况。
这种情况通常是由于JOIN或聚合操作之后结果集中字段重名引起的。由于DataWorks无法确定哪个字段对应哪个表,因此它会简单地将重复字段合并在一起,可能导致数据覆盖。
为了避免这种情况发生,建议您在JOIN或聚合操作之前给每个表的字段添加别名,以确保字段名称唯一。例如:
这样,在结果集中就不会出现字段重名的情况,也不会发生数据覆盖。
另外,您还可以通过调整JOIN或聚合操作的顺序和规则,以确保数据不会发生覆盖。例如,可以优先JOIN具有较少记录的表,并尽可能保留原始字段名称,以防止字段重名。
查询了两个字段 实际只展示了一个字段是吗 运行日志里有份logview 辛苦点开看下里面的result是几列,此回答整理自钉群“DataWorks交流群(答疑@机器人)”