tongchenkeji 发表于:2022-9-29 10:39:050次点击 已关注取消关注 关注 私信 请问如果我同步的hive表是分区表,分区字段是insert date,在配置离线同步界面应该怎么弄呀[阿里云DataWorks] 暂停朗读为您朗读 请问如果我同步的hive表是分区表,分区字段是insert date,在配置离线同步界面应该怎么弄呀?这样好像不太对 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 DataWorks# HIVE122# SQL1285# 大数据开发治理平台 DataWorks3946
六月的雨在钉钉AM 2023-11-27 21:16:31 1 在配置离线同步任务之前,首先需要确认待同步数据源支持的数据源与读写能力,MaxCompute支持离线同步的单表读、单表写 而整库离线同步方案包括周期性全量同步、周期性增量同步、一次性全量同步、一次性增量同步、一次性全量周期性增量同步。这里根据操作步骤如何将整库数据离线同步至MaxCompute,具体步骤参考https://help.aliyun.com/document_detail/302449.html,由于你操作不熟练,建议参考官方文档逐步操作,加深记忆,防止出错,文档中明确了每一步的任务,逐步执行即可
穿过生命散发芬芳AM 2023-11-27 21:16:31 2 1、在DataWorks的数据开发页面,新建一个业务流程。 2、新建一个离线同步任务。 – 展开新建的业务流程,右键单击数据集成,选择新建 > 离线同步。 – 在新建节点对话框中,输入节点名称,单击提交。 3、在选择数据源区域中,将数据来源指定为HIVE数据源,并填入待同步的表名称;将数据去向指定为ODPS数据源,并填入索引名和索引类型。 详细步骤可以参考该链接
三掌柜666AM 2023-11-27 21:16:31 3 同步的hive表是分区表,分区字段是insert date,在配置离线同步界面,这个楼主可以直接去阿里云对应的文档中查看啊,文档里面写的很清楚,这里就不贴具体链接了。
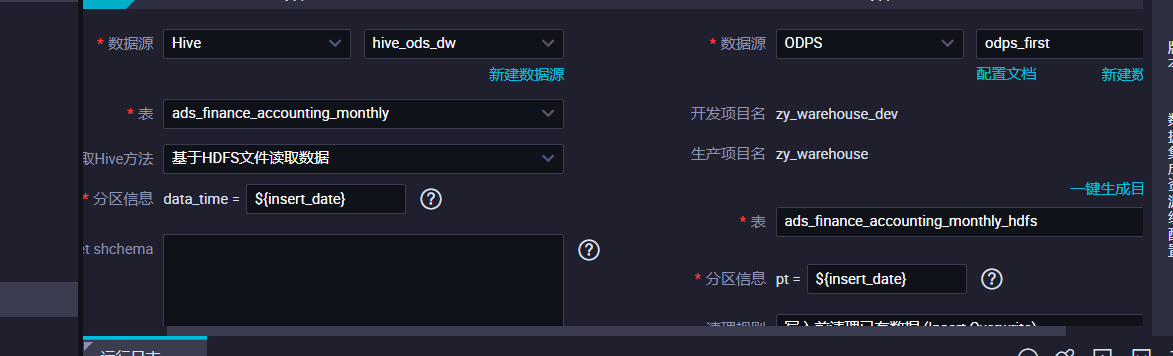
在配置离线同步任务之前,首先需要确认待同步数据源支持的数据源与读写能力,MaxCompute支持离线同步的单表读、单表写 而整库离线同步方案包括周期性全量同步、周期性增量同步、一次性全量同步、一次性增量同步、一次性全量周期性增量同步。这里根据操作步骤如何将整库数据离线同步至MaxCompute,具体步骤参考https://help.aliyun.com/document_detail/302449.html,由于你操作不熟练,建议参考官方文档逐步操作,加深记忆,防止出错,文档中明确了每一步的任务,逐步执行即可
1、在DataWorks的数据开发页面,新建一个业务流程。 2、新建一个离线同步任务。 – 展开新建的业务流程,右键单击数据集成,选择新建 > 离线同步。 – 在新建节点对话框中,输入节点名称,单击提交。 3、在选择数据源区域中,将数据来源指定为HIVE数据源,并填入待同步的表名称;将数据去向指定为ODPS数据源,并填入索引名和索引类型。
详细步骤可以参考该链接
同步的hive表是分区表,分区字段是insert date,在配置离线同步界面,这个楼主可以直接去阿里云对应的文档中查看啊,文档里面写的很清楚,这里就不贴具体链接了。
欢迎查看阿里云帮助文档, 最佳实践部分有具体使用例子