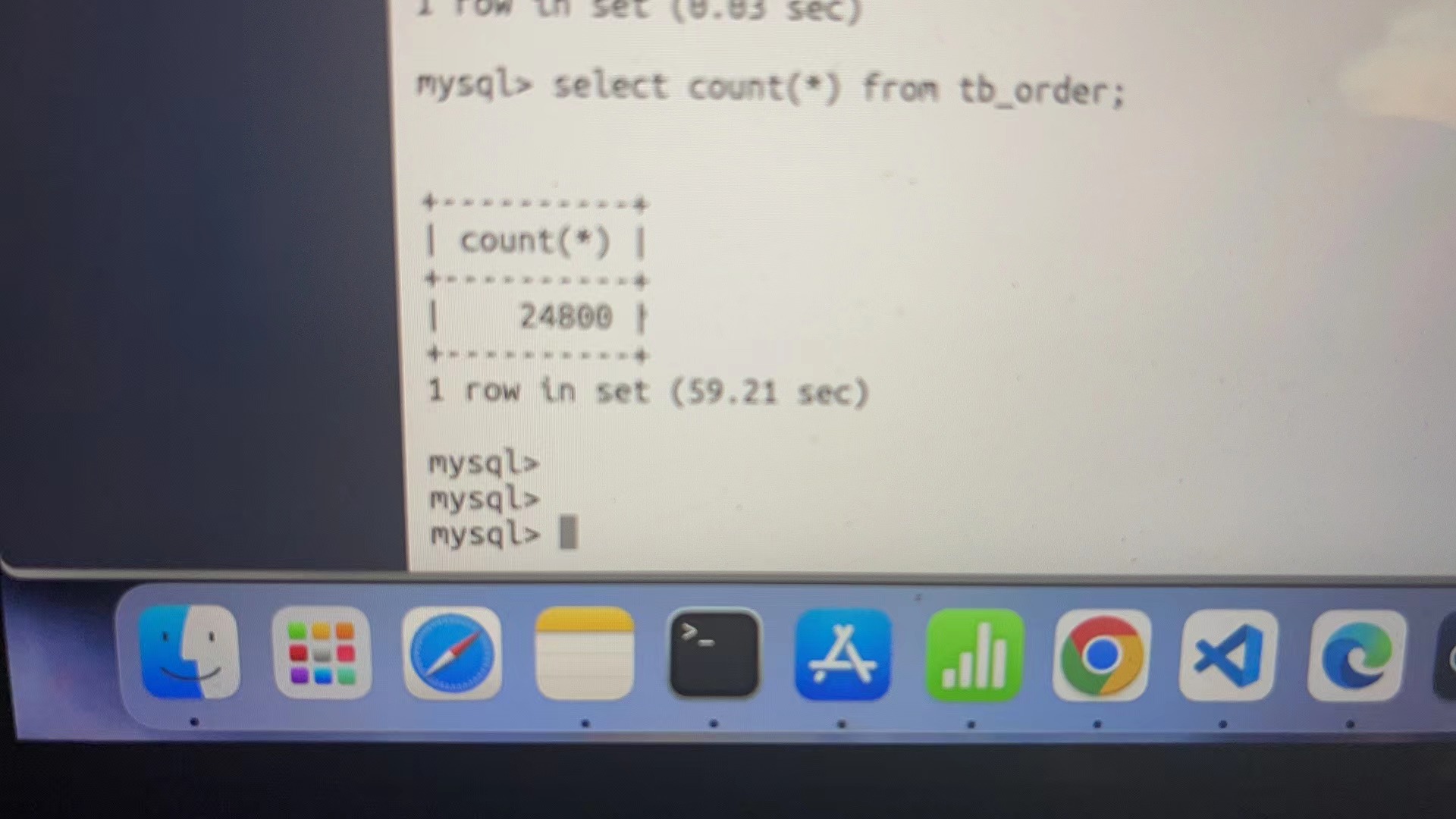
 在PolarDB中2.8万条数据 count 查了一分钟,这样的性能真能在生产环境用吗?4c32g配置的电脑我搭了几次。性能都不行。不知道是姿势不对还是啥情况?总共就几万行 相同的机器。相同的程序测试各种不同的数据库。 原生MySQL。100万行。count也就0.3秒 问题二:你这条查询会下推给dn计算的,cn基本不耗内存,你是不是顺手把dn内存调大了?
在PolarDB中2.8万条数据 count 查了一分钟,这样的性能真能在生产环境用吗?4c32g配置的电脑我搭了几次。性能都不行。不知道是姿势不对还是啥情况?总共就几万行 相同的机器。相同的程序测试各种不同的数据库。 原生MySQL。100万行。count也就0.3秒 问题二:你这条查询会下推给dn计算的,cn基本不耗内存,你是不是顺手把dn内存调大了?
在PolarDB中2.8万条数据 count 查了一分钟,这样的性能真能在生产环境用吗?[阿里云PolarDB]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
在PolarDB中2.8万条数据 count 查了一分钟的性能,取决于多个因素,例如硬件配置、数据库表结构、索引设计、查询语句优化等等。因此,不能简单地根据这个结果来判断这样的性能是否能在生产环境使用。
但是,从查询时间来看,一分钟内完成2.8万条数据的 count 查询是比较慢的。如果这个查询需要经常执行,会对数据库的性能产生影响。因此,建议对查询进行优化,例如添加合适的索引、分区等措施,以提高查询效率。同时,也需要考虑其他因素,例如服务器负载、网络带宽等,以确保整个系统的性能能够满足业务需求。
PolarDB是阿里云自研的全新一代云数据库,性能最高提升至MySQL的6倍,满足企业级OLTP(在线事务处理)并兼顾结构化数据并发查询场景。在实测跑分上,POLARDB读写性能均超越同级产品,读终极性能实现100万QPS,写性能实现13万QPS,领先同行。
根据您提供的信息,PolarDB 查询性能较慢,可能需要进一步排查和分析。
首先,对于 count 查询,通常需要下推给 DN(Data Node) 进行计算,因此查询时间可能会受到 DN 的性能和资源限制的影响。在 PolarDB 中,DN 的性能和资源限制可以通过配置 DN 的内存、CPU 和磁盘等资源来控制。因此,如果您发现在查询时 DN 的性能和资源不足,可能会导致查询时间较长。
其次,对于性能问题,建议进行进一步排查和分析。
在PolarDB等关系型数据库中,对大量数据进行count操作可能会导致性能问题。在您的情况下,2.8万条数据的count操作需要一分钟完成,这显然不是可接受的性能水平,并且可能无法在生产环境中使用。
以下是一些可能导致性能问题的因素:
数据库表结构设计不合理或索引缺失,导致查询效率低下。
查询语句中存在复杂的连接、子查询或聚合函数,导致性能下降。
数据库服务器硬件配置不足,包括CPU、内存和磁盘I/O等方面。
数据库连接池设置不合理或连接数过多,导致竞争资源。
为了解决这个性能问题,您可以尝试以下几种方法:
优化数据库表结构和索引设计,确保查询操作能够快速地定位到目标行。
尽量避免使用复杂的连接、子查询或聚合函数,尽可能简化查询语句。
确保数据库服务器具备足够的硬件资源,比如增加CPU核心数、内存容量和使用高速磁盘等。
调整数据库连接池设置,合理限制并发连接数,避免竞争资源。
考虑使用分布式数据库或缓存技术,将查询操作分布到多个节点或缓存中。
PolarDB 是一个基于 PostgreSQL 构建的分布式数据库,主要用于处理大规模数据和提供高可用性。但是,性能问题取决于多个因素,如数据量、表结构、查询方式等。
对于您描述的情况,一次 count 查询需要一分钟的时间,这显然不是一种性能表现良好的方式。在生产环境中,这样的性能可能会对应用程序的性能产生负面影响,并可能导致用户的不满。
为了优化性能,您可以考虑以下几种方法:
总之,PolarDB 的性能取决于多个因素,您可以通过优化表结构、分区表、优化查询、增加硬件资源以及水平扩展等方式来提高性能。
这个问题需要根据实际情况和需求来评估。首先需要分析查询语句的复杂度和表结构、索引情况,以及数据库的大小和配置等因素,来确定查询时间是否合理。
在一些情况下,查询数万条数据确实需要一定时间,这可能是由于数据量过大、查询语句复杂、缺乏合适的索引等原因导致。但是,如果在生产环境下频繁出现这样的性能问题,可能会对业务产生严重影响,需要进一步优化数据库设计和查询语句,或考虑升级硬件配置,以提升查询性能。
一般来说,查询时间越短越好,但在实际情况下,我们需要权衡查询效率和数据准确性,以满足业务需求。如果查询时间过长,需要根据具体情况来评估和优化数据库性能。
PolarDB是一款基于PostgreSQL的关系型数据库,而count操作通常需要扫描数据以统计记录的数量,性能开销取决于多个因素,例如表结构、数据量、查询优化等。因此,评估性能不能简单地以一个特定的指标为基础,还需要考虑实际使用场景和业务需求。
对于2.8万条数据的count操作需要一分钟的情况,这个性能确实相对较低。可能的原因包括表结构设计不合理、索引未正确使用、查询语句不够优化等。在生产环境中使用PolarDB时,建议进行充分的性能测试和优化,以确保数据库能够满足业务需求。
为了提高性能,可以采取以下措施:
优化表结构:确保表结构和索引设计合理,避免冗余数据和重复存储。 优化查询语句:使用EXPLAIN分析查询语句的执行计划,找出性能瓶颈并进行优化。 分区表和分片:对于大型表,可以考虑分区和分片来提高查询性能。 监控和调优:定期监控数据库的性能指标,及时发现和解决性能问题。 总之,PolarDB的性能取决于多个因素,需要进行充分的优化和测试,以确保在生产环境中能够满足业务需求。
您好,查询性能的问题可能与多方面因素有关,以下是一些可能导致查询性能下降的因素:
数据库索引:如果您的表没有合适的索引,查询性能会受到影响。建议您检查一下表的索引情况,是否有需要添加或优化的索引。
查询语句:查询语句的写法也会影响查询性能。例如,在执行 COUNT(*) 时,如果没有使用 WHERE 子句进行过滤,查询会扫描整个表,导致性能下降。建议您优化查询语句,尽量减少数据扫描量。
硬件资源:查询性能也与硬件资源有关。如果您的硬件资源不足,例如 CPU、内存等,会导致查询性能下降。建议您检查一下服务器的硬件配置是否满足要求。
关于第二个问题,DN 实例是负责数据存储和计算的节点,CN 实例是负责 SQL 解析和优化的节点。在执行 COUNT() 查询时,DN 实例会扫描数据进行计算,CN 实例则不会承担太大的计算压力。因此,如果 DN 实例内存不足,也会导致 COUNT() 查询性能下降。建议您检查一下 DN 实例的内存配置是否满足要求。
从性能的角度来看,一分钟查询2.8万条数据的耗时确实有些长。是否适合在生产环境使用,需要根据具体情况来判断。
针对问题一的回答试下加force index (primary) 针对问题二的回答: 是的,现在这个配置。会比较稳定cn dn 都是4g这就正常了此回答整理自微信群“阿里云 PolarDB-X开源交流2号群”
对于第一个问题,PolarDB的性能在大部分情况下是能够满足生产环境的需求的。但是,查询性能受很多因素影响,比如数据规模、索引质量、硬件配置、查询语句等等。在查询2.8万条数据进行count操作时,如果查询时间长达一分钟,可能是因为缺乏合适的索引、硬件配置不足或者查询语句有问题等原因导致的。建议检查查询语句是否合理,是否存在大表关联、子查询或者其他复杂操作,是否存在慢查询、死锁等问题,以及是否有足够的硬件配置(CPU、内存、IO等)。
对于第二个问题,PolarDB在执行查询时会将一部分计算下推到DN节点进行计算,以减少CN节点的压力。在这种情况下,增加DN节点的内存确实可以提升查询性能。但是,需要根据具体情况进行调优,增加内存并不一定能够显著提升性能,还需要综合考虑其他因素。建议在进行性能调优时,可以通过查看PolarDB的性能监控指标,包括CPU、内存、IO、网络等方面的指标,来了解系统瓶颈所在,并进行相应的优化。
这个肯定不可以的,可以优化下效率,比如:
索引优化:确保表中的列上存在适当的索引。索引可以加快查询的速度。分析查询语句和数据访问模式,为常见的过滤条件创建适当的索引。
查询优化:审查查询语句并确保它们是有效且高效的。使用适当的查询语句和关键字,避免全表扫描和不必要的数据加载。
硬件升级:考虑升级数据库服务器的硬件配置,例如增加内存、CPU 或更快的存储系统,以提高数据库的整体性能。
数据库参数调整:根据数据库引擎和配置,调整相关的数据库参数,以适应具体的负载和性能需求。
数据库分区:如果适用,可以考虑使用数据库分区来分散数据和查询负载,提高查询性能。
数据库缓存:合理配置数据库缓存,例如适当设置查询缓存或结果缓存,以减少对磁盘的读取操作。
数据库复制和负载均衡:使用数据库复制和负载均衡技术来分担读取负载,提高整体性能。