请问一下机器学习PAI DSSM模型负采样item表的schema要求是什么?负采样item表的字段是不是要求都在训练数据表里出现并且在data_configs里进行配置?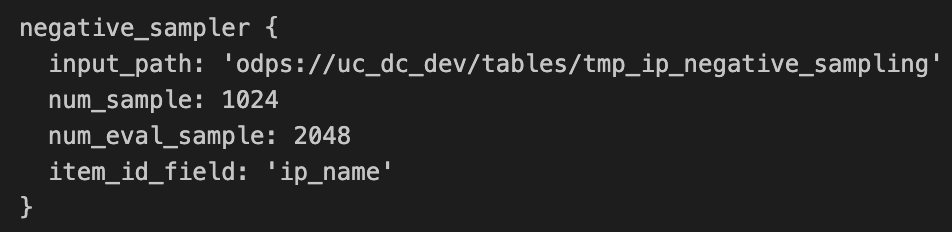
请问一下机器学习PAI DSSM模型负采样item表的schema要求是什么?[阿里云机器学习PAI]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
![]()
请问一下机器学习PAI DSSM模型负采样item表的schema要求是什么?负采样item表的字段是不是要求都在训练数据表里出现并且在data_configs里进行配置?
是的,此回答整理自钉群“【EasyRec】推荐算法交流群”
在 MaxCompute PAI DSSM 模型中,负采样 item 表的 schema 不一定要完全与训练数据表相同。但是,通常来说,负采样表的列应该至少包含训练数据表中的文本特征列,以便于 DSSM 对比评估。同时,如果负采样表中的列名不同于训练数据表中的列名,则需要在 data_configs 配置中进行映射,以便于模型识别和比较。
以下是负采样 item 表的基本要求:
以下是一个负采样 item 表的例子:
其中 id 代表样本的唯一标识符(ID),title 和 description 则分别是文本特征列。