tongchenkeji 发表于:2023-11-19 14:52:270次点击 已关注取消关注 关注 私信 请问一下机器学习PAI DSSM负采样的例子当中,这个表的sample有么?[阿里云机器学习PAI] 暂停朗读为您朗读 请问一下机器学习PAI DSSM负采样的例子当中,这个表的sample有么?我们对于如何组织负采样的样本和column有些迷惑: 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 机器学习PAI# 人工智能平台 PAI1410# 机器学习深度学习1219
xin在这AM 2023-11-28 2:43:40 1 那个是离线文本你在odps上跑的话,建这样一个表就行了 建这样的一个表,格式如上.注意特征分隔符别跟特征本身冲突了.你如果用fg的话,我记得默认的分隔符好像是chr(2).,此回答整理自钉群“【EasyRec】推荐算法交流群”
小周sirAM 2023-11-28 2:43:40 2 在 DSSM 模型中,负采样通常用于生成候选匹配项列表,用于对比评估原始匹配项的相关性。一般来说,负采样表应该包含两个主要的部分: 表头(header): 这部分包含了列名和其他相关信息。 数据(data): 这部分包含了负采样结果的具体数据。 以下是一个简单的负采样表的例子: id text 1 我们是一支专业的团队 2 一支拥有丰富经验的团队 3 一支技术精湛的团队 4 一支追求卓越的团队 5 一支值得信赖的团队 在这个例子中,id 列代表了每个样本的唯一标识符(ID),text 列则包含了用于 DSSM 训练的文本特征。训练时,DSSM 会对原始匹配项(如“一支专业高效的团队”) 和 负采样表中的每一个文本特征进行对比评估,以找出最相似的文本特征。建议在构建负采样表时保持一致性,确保每一列都有清晰明确的意义,并且所含有的数据量足够大,以便有效地评估 DSSM 的性能。还可以根据具体需求调整负采样表的结构,例如添加更多的列或进行更细致的分类等。
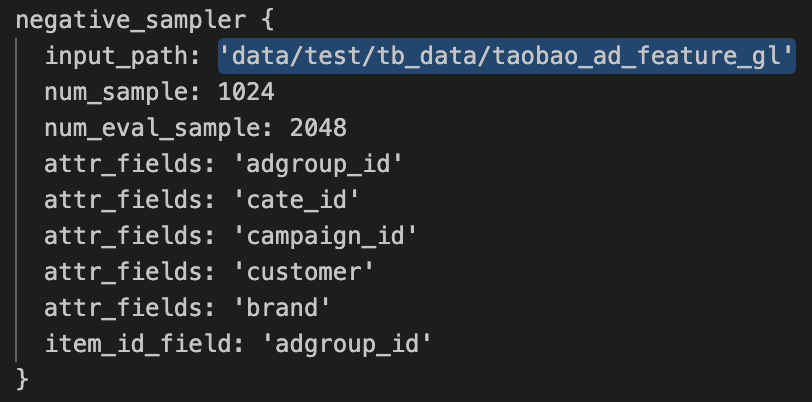
那个是离线文本你在odps上跑的话,建这样一个表就行了
建这样的一个表,格式如上.注意特征分隔符别跟特征本身冲突了.你如果用fg的话,我记得默认的分隔符好像是chr(2).,此回答整理自钉群“【EasyRec】推荐算法交流群”
在 DSSM 模型中,负采样通常用于生成候选匹配项列表,用于对比评估原始匹配项的相关性。一般来说,负采样表应该包含两个主要的部分:
以下是一个简单的负采样表的例子:
在这个例子中,id 列代表了每个样本的唯一标识符(ID),text 列则包含了用于 DSSM 训练的文本特征。训练时,DSSM 会对原始匹配项(如“一支专业高效的团队”) 和 负采样表中的每一个文本特征进行对比评估,以找出最相似的文本特征。
建议在构建负采样表时保持一致性,确保每一列都有清晰明确的意义,并且所含有的数据量足够大,以便有效地评估 DSSM 的性能。还可以根据具体需求调整负采样表的结构,例如添加更多的列或进行更细致的分类等。