tongchenkeji 发表于:2023-6-5 15:41:480次点击 已关注取消关注 关注 私信 在机器学习PAI有个算子处理数据不均衡,请问这是什么原因呢?[阿里云机器学习PAI] 暂停朗读为您朗读 在机器学习PAI有个算子处理数据不均衡,请问这是什么原因呢? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 机器学习PAI# 人工智能平台 PAI1410# 机器学习深度学习1219
wljslmzAM 2023-11-28 2:52:22 1 在阿里云机器学习平台 PAI 中,某些算子(例如分类算法中的决策树、逻辑回归等)会对数据样本进行划分和训练,但是如果数据集中正负样本比例不均衡,就可能会导致算法过度偏向数量较多的类别,从而影响模型的准确性和泛化能力。 具体来说,数据不均衡问题可能导致以下两个方面的影响: 训练偏差:由于样本数量较少的类别相对于数量较多的类别来说在训练时占比较小,因此算法可能会过度注重数量较多的类别,使得样本数量较少的类别无法得到足够的关注和训练,导致模型对这些类别的分类效果较差。 测试错误率:由于测试数据集中正负样本的比例也有可能不均衡,因此如果模型在训练时过于依赖数量较多的类别,则在测试过程中可能会出现误判数量较少的类别的情况,从而导致整体测试错误率的提高。 解决数据不均衡问题的方法有很多,例如: 对数量较少的样本进行上采样或人工合成,增加样本数量。 对数量较多的样本进行下采样或剔除一部分,减少样本数量。 在算法中添加类别权重,使得模型对每个类别的分类效果更加均衡。 使用集成学习等方法综合考虑不同样本的贡献,提高模型的泛化性能。 在阿里云机器学习平台 PAI 中,也提供了一些解决数据不均衡问题的算子和工具,例如集成学习算法 XGBoost、LightGBM 等,在使用时建议根据实际情况选择合适的算法和方法,并进行适当的参数调优和模型评估,以获得更好的预测结果。
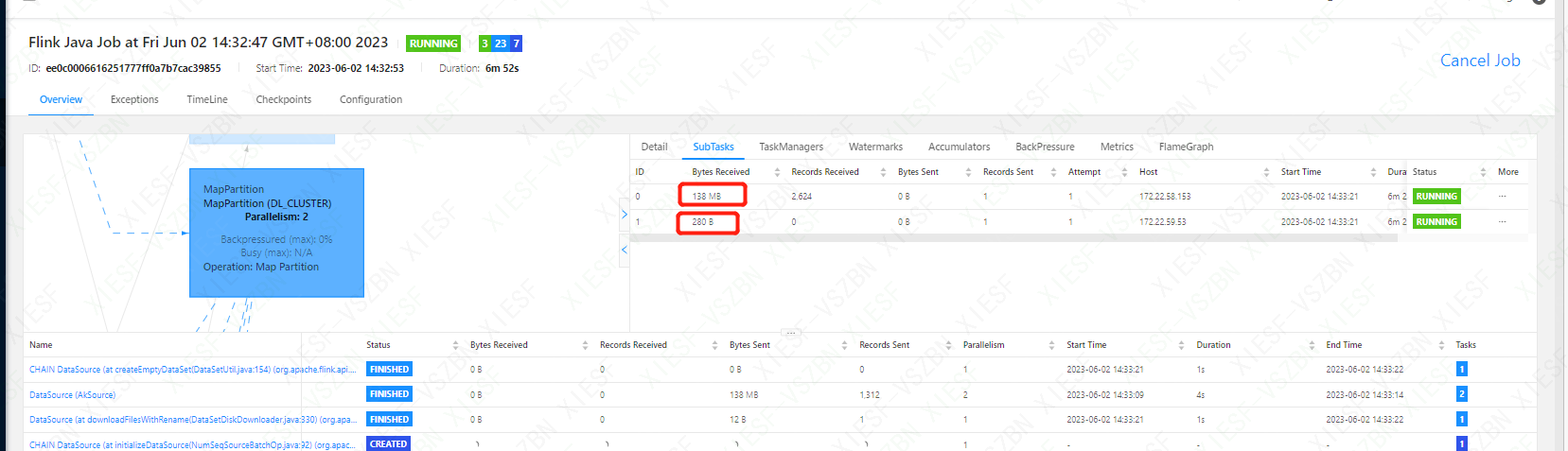
在阿里云机器学习平台 PAI 中,某些算子(例如分类算法中的决策树、逻辑回归等)会对数据样本进行划分和训练,但是如果数据集中正负样本比例不均衡,就可能会导致算法过度偏向数量较多的类别,从而影响模型的准确性和泛化能力。
具体来说,数据不均衡问题可能导致以下两个方面的影响:
训练偏差:由于样本数量较少的类别相对于数量较多的类别来说在训练时占比较小,因此算法可能会过度注重数量较多的类别,使得样本数量较少的类别无法得到足够的关注和训练,导致模型对这些类别的分类效果较差。
测试错误率:由于测试数据集中正负样本的比例也有可能不均衡,因此如果模型在训练时过于依赖数量较多的类别,则在测试过程中可能会出现误判数量较少的类别的情况,从而导致整体测试错误率的提高。
解决数据不均衡问题的方法有很多,例如:
在阿里云机器学习平台 PAI 中,也提供了一些解决数据不均衡问题的算子和工具,例如集成学习算法 XGBoost、LightGBM 等,在使用时建议根据实际情况选择合适的算法和方法,并进行适当的参数调优和模型评估,以获得更好的预测结果。
可能数据本身就不均衡,可以加个 xxx.rebalance() 来重新分配数据。此回答整理自钉群“Alink开源–用户群”