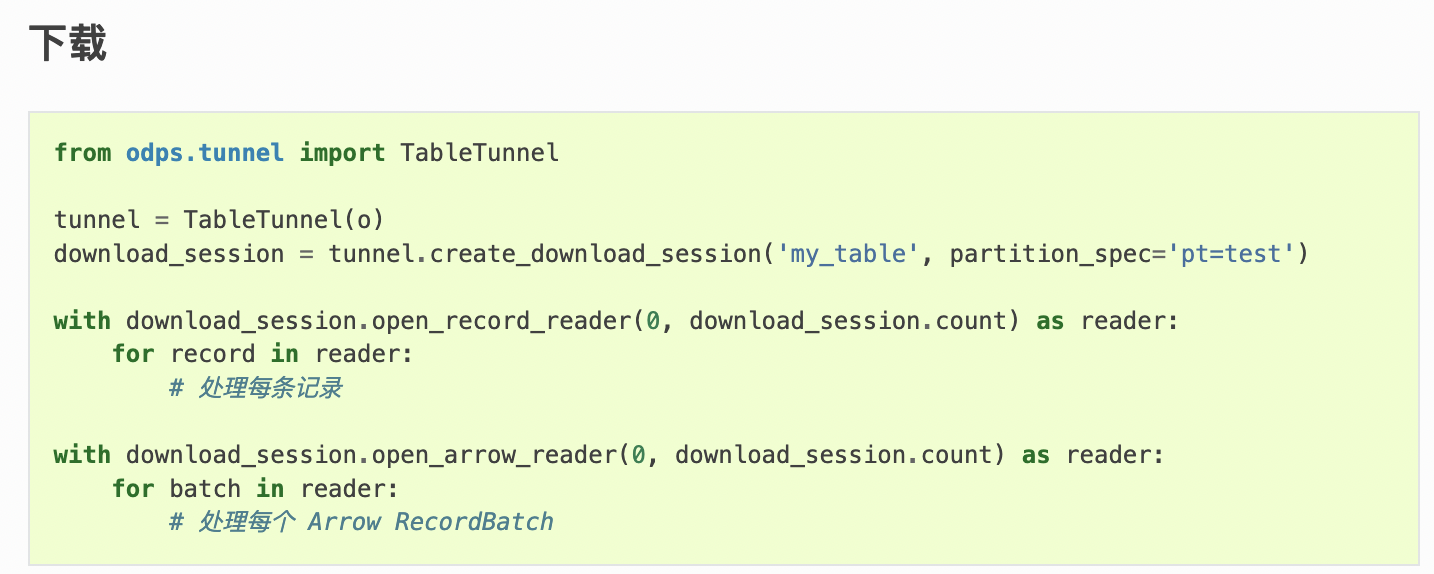
tongchenkeji 发表于:2023-7-30 18:06:470次点击 已关注取消关注 关注 私信 机器学习PAI后面基本都是# 处理每条记录 的注释,你们这个的文件是怎么生成的啊?[阿里云机器学习PAI] 暂停朗读为您朗读 机器学习PAI后面基本都是# 处理每条记录 的注释,你们这个taobao_ad_feature_gl的文件是怎么生成的啊? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 机器学习PAI# 人工智能平台 PAI1410# 机器学习深度学习1219
Star时光AM 2023-11-28 2:53:35 1 通常情况下,在机器学习 PAI 平台上生成文件的过程可能涉及以下几个步骤: 数据预处理:首先,您需要对原始数据进行适当的预处理,包括清洗、转换和格式化等操作,以使其符合模型的要求。 特征工程:在数据预处理之后,根据任务需求进行特征工程,即从原始数据中提取有意义的特征。这可以包括计算新的特征、编码类别特征、标准化数值特征等。 数据转换和组织:根据训练和评估的需求,将数据转换为适当的格式,如适应模型输入的特定形状和类型。同时,根据数据量的大小和存储要求,将数据组织成合适的结构。 文件生成:最后一步是将经过处理和转换的数据写入文件。这可以使用编程语言、数据处理框架或平台提供的相应函数、API 或工具来实现。
xin在这AM 2023-11-28 2:53:35 2 $ odpscmd -e “tunnel help download” 我们就是按照这个方式拼的,Schema为: id:int64 | weight:float | attrs:string,其中attr为”:”分隔符拼接的Item特征,此回答整理自钉群“【EasyRec】推荐算法交流群”
通常情况下,在机器学习 PAI 平台上生成文件的过程可能涉及以下几个步骤:
数据预处理:首先,您需要对原始数据进行适当的预处理,包括清洗、转换和格式化等操作,以使其符合模型的要求。
特征工程:在数据预处理之后,根据任务需求进行特征工程,即从原始数据中提取有意义的特征。这可以包括计算新的特征、编码类别特征、标准化数值特征等。
数据转换和组织:根据训练和评估的需求,将数据转换为适当的格式,如适应模型输入的特定形状和类型。同时,根据数据量的大小和存储要求,将数据组织成合适的结构。
文件生成:最后一步是将经过处理和转换的数据写入文件。这可以使用编程语言、数据处理框架或平台提供的相应函数、API 或工具来实现。
$ odpscmd -e “tunnel help download” 我们就是按照这个方式拼的,Schema为: id:int64 | weight:float | attrs:string,其中attr为”:”分隔符拼接的Item特征,此回答整理自钉群“【EasyRec】推荐算法交流群”