在文字识别ocr中,sdk调接口的时候报这个错是为什么呢?:{“code”:”10001″,”message”:”参数出错”,”requestId”:”FDEEBC37-AA20-54E5-AAEF-45DA5E452722″}}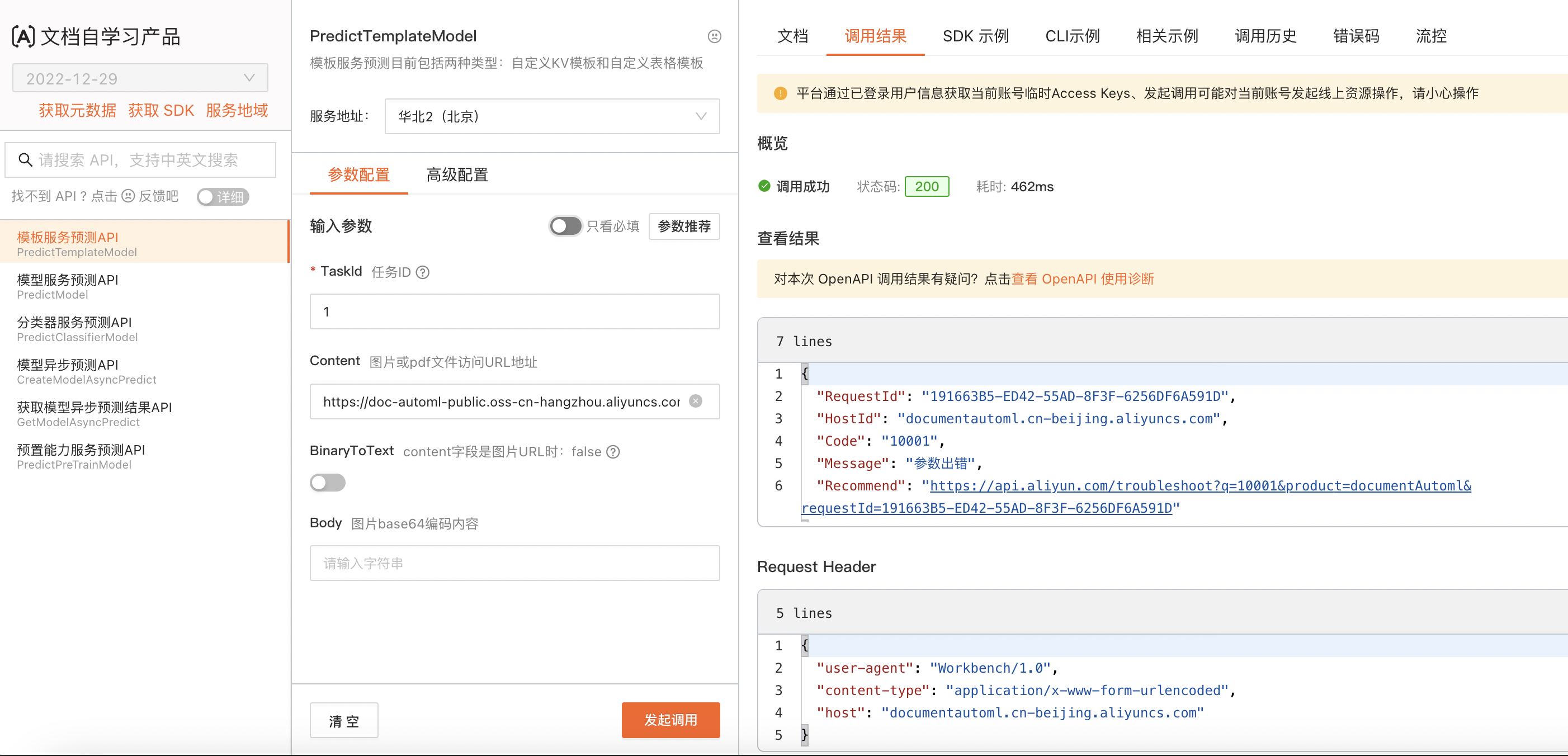
在文字识别ocr中,sdk调接口的时候报这个错是为什么呢?[阿里云OCR]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
![]()
在文字识别ocr中,sdk调接口的时候报这个错是为什么呢?:{“code”:”10001″,”message”:”参数出错”,”requestId”:”FDEEBC37-AA20-54E5-AAEF-45DA5E452722″}}
这个错误代码代表参数无效。这可能是由于以下原因引起的:
你可以检查一下以下几点:
这是指输入参数不合法导致的错误。您需要检查输入参数的正确性,确保它们符合阿里云 OCR 文字识别 API 接口的要求,并确保您的账号已经授权使用该服务。
10001 参数出错
OpenAPI 问题诊断
推荐使用包含 RequestID 的错误信息进行诊断,可获得更完整的诊断结果。https://next.api.aliyun.com/troubleshoot?spm=api-workbench.API%20Document.0.0.ad737a57EjfwbV&q=10001&product=documentAutoml&version=2022-12-29
BinaryToText为非必填项
content字段和body字段传参二选一,图片URL则content为图片访问地址。内容为base64编码则传参body,且BinaryToText传true
pdf 限制20Mb 10页 除了长文档类型的模型预测以外 其他预测服务只会取第一页进行预测
200 10001 参数出错
查一下必填字段是不是写错了,大概路是这方面的问题
也可以在全局诊断中判断一下哪里出错了—来自全局错误码文档介绍