tongchenkeji 发表于:2023-8-20 15:54:250次点击 已关注取消关注 关注 私信 文字识别OCR只能上传图片,不支持pdf文档吗?[阿里云OCR] 暂停朗读为您朗读 文字识别OCR只能上传图片,不支持pdf文档吗? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940
六月的雨在钉钉AM 2023-11-28 3:15:00 1 您好,文字识别OCR识别接口通常均支持图片格式数据,包括:.jpg/.jpeg/.png/.bmp./gif./tiff./webp,请注意图片大小不超过10M,最短边大于15像素,最长边不超过8192像素;比如 部分接口支持PDF|PDF格式,包括 增值税发票识别、混贴发票识别、火车票识别、航空行程单识别、定额发票识别、通用机打发票识别、增值税发票卷票识别 更多详细内容参考文档:文档
Star时光AM 2023-11-28 3:15:00 3 阿里云的文字识别OCR服务支持上传图片进行文字提取,以及光学字符识别。目前,OCR服务不直接支持上传PDF文档进行识别。 如果您有需要将PDF文档中的文字提取出来,可以考虑先将PDF文档转换为图片格式,然后再使用OCR服务对这些图片进行文字提取。您可以使用工具或库将PDF文档转换为图片文件(如JPEG或PNG格式),然后将这些图片作为输入传递给OCR服务。 将PDF转换为图片的方法有很多,您可以选择使用开源的工具或编程语言中的相关库来实现。一旦将PDF转换为图像文件,您可以将这些图像文件依次上传到OCR服务进行文字识别。 需要注意的是,将PDF转换为图像时,要确保图像质量良好,并且文字清晰可见。较高分辨率的图像通常会得到更准确的识别结果。 在实际操作中,您可以按照以下步骤进行: 使用合适的工具或库将PDF文档转换为图像文件。 依次将转换后的图像文件上传至OCR服务进行文字识别。 解析OCR服务返回的结果,获取提取到的文字内容。 通过这种方式,您可以利用OCR服务来提取PDF文档中的文字信息。请注意,这可能会涉及到多个图像和OCR请求,取决于PDF文档的页数和内容。
魏红斌AM 2023-11-28 3:15:00 4 从文档中提取出逻辑层级结构、文本内容、表格内容、 Key-value键值字段、样式信息等。基于对文档的内容信息、版面信息和逻辑信息的分析理解,以结构化数据的形态输出抽取结果。支持100M、100页之内的PDF文档,以及30张之内的图片文档格式。文档智能解析接口可进行通用文档抽取和理解,从文档中提取出层级结构、文本内容、KV字段、样式信息等。 文档智能解析接口为异步接口,需要先调用文档智能解析异步提交服务SubmitDocStructureJob接口进行异步任务提交,然后调用文档智能解析结果查询服务GetDocStructureResult接口进行结果轮询,建议每10秒轮询一次,最多轮询120分钟,如果120分钟还未查询到处理完成结果,则视为处理超时。 当异步任务处理提交后,用户可以在处理结束后的24小时之内查询处理结果,超过24小时后将无法查询到处理结果。
小周sirAM 2023-11-28 3:15:00 5 阿里云的文字识别OCR接口支持上传图片进行文字识别,但不直接支持上传PDF文档。您可以将PDF文档转换为图片格式后,再将其上传至OCR接口进行处理。 一种常见的方法是使用PDF处理工具或库,如PyPDF2、pdf2image等,将PDF文档中的每一页转换为图片。然后,您可以将生成的图片作为输入,通过阿里云的OCR接口进行文字识别。 以下是大致的步骤说明: 使用合适的PDF处理工具(如PyPDF2)读取PDF文档,并逐页将其转换为图像。这些工具通常提供了将PDF页转换为图像的功能,例如将PDF页面保存为JPEG、PNG等常见图像格式。 针对每个生成的图像,调用阿里云的文字识别OCR接口,提交图像进行文字识别。确保在请求参数中设置正确的识别类型和其他相关参数。 解析并处理OCR接口返回的识别结果。根据您的需求,提取需要的文本信息或执行进一步的数据处理操作。 需要注意的是,PDF转换为图片时,应确保图像质量高且清晰可见,以获得更准确的文字识别结果。此外,如果PDF文档较大,可能需要考虑分页处理和批量上传的方式,以避免接口调用的限制。
wljslmzAM 2023-11-28 3:15:00 6 对于阿里云的文字识别OCR服务,目前仅支持上传图片进行文字识别,不直接支持上传PDF文档。您可以将PDF文档转换为图片格式,然后再使用文字识别OCR服务进行文字提取。 以下是将PDF文档转换为图片的一种方法: 使用PDF处理工具:使用第三方的PDF处理工具,如Adobe Acrobat、Foxit PhantomPDF等,将需要识别的PDF文档转换为图片格式(如JPEG、PNG等),通常这些工具都提供了将PDF页面转为图片的选项。 在线转换工具:通过在线的PDF转图片工具,将PDF文档上传并选择将其转换为图片格式。一些在线转换工具如Smallpdf、Zamzar、iLovePDF等都提供PDF转图片的功能,您可以在浏览器中搜索并选择适合您的工具。 编程实现:使用编程语言和相关的库,如Python中的pdf2image库、PyPDF2库等,将PDF文档转换为图片。这样您可以在自己的程序中实现自动的PDF转图片功能。 无论采用哪种方法,一旦将PDF转换为图片格式,就可以将生成的图片上传到阿里云的文字识别OCR服务进行文字提取和识别。
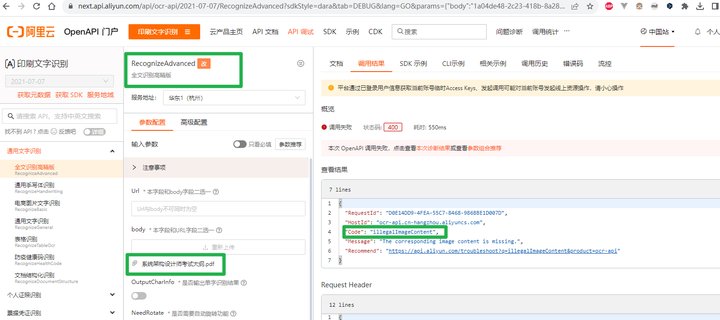
您好,文字识别OCR识别接口通常均支持图片格式数据,包括:.jpg/.jpeg/.png/.bmp./gif./tiff./webp,请注意图片大小不超过10M,最短边大于15像素,最长边不超过8192像素;比如
部分接口支持PDF|PDF格式,包括 增值税发票识别、混贴发票识别、火车票识别、航空行程单识别、定额发票识别、通用机打发票识别、增值税发票卷票识别
更多详细内容参考文档:文档
只支持图片-此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”
阿里云的文字识别OCR服务支持上传图片进行文字提取,以及光学字符识别。目前,OCR服务不直接支持上传PDF文档进行识别。
如果您有需要将PDF文档中的文字提取出来,可以考虑先将PDF文档转换为图片格式,然后再使用OCR服务对这些图片进行文字提取。您可以使用工具或库将PDF文档转换为图片文件(如JPEG或PNG格式),然后将这些图片作为输入传递给OCR服务。
将PDF转换为图片的方法有很多,您可以选择使用开源的工具或编程语言中的相关库来实现。一旦将PDF转换为图像文件,您可以将这些图像文件依次上传到OCR服务进行文字识别。
需要注意的是,将PDF转换为图像时,要确保图像质量良好,并且文字清晰可见。较高分辨率的图像通常会得到更准确的识别结果。
在实际操作中,您可以按照以下步骤进行:
通过这种方式,您可以利用OCR服务来提取PDF文档中的文字信息。请注意,这可能会涉及到多个图像和OCR请求,取决于PDF文档的页数和内容。
从文档中提取出逻辑层级结构、文本内容、表格内容、 Key-value键值字段、样式信息等。基于对文档的内容信息、版面信息和逻辑信息的分析理解,以结构化数据的形态输出抽取结果。支持100M、100页之内的PDF文档,以及30张之内的图片文档格式。文档智能解析接口可进行通用文档抽取和理解,从文档中提取出层级结构、文本内容、KV字段、样式信息等。
文档智能解析接口为异步接口,需要先调用文档智能解析异步提交服务SubmitDocStructureJob接口进行异步任务提交,然后调用文档智能解析结果查询服务GetDocStructureResult接口进行结果轮询,建议每10秒轮询一次,最多轮询120分钟,如果120分钟还未查询到处理完成结果,则视为处理超时。
当异步任务处理提交后,用户可以在处理结束后的24小时之内查询处理结果,超过24小时后将无法查询到处理结果。
阿里云的文字识别OCR接口支持上传图片进行文字识别,但不直接支持上传PDF文档。您可以将PDF文档转换为图片格式后,再将其上传至OCR接口进行处理。
一种常见的方法是使用PDF处理工具或库,如
PyPDF2、pdf2image等,将PDF文档中的每一页转换为图片。然后,您可以将生成的图片作为输入,通过阿里云的OCR接口进行文字识别。以下是大致的步骤说明:
使用合适的PDF处理工具(如
PyPDF2)读取PDF文档,并逐页将其转换为图像。这些工具通常提供了将PDF页转换为图像的功能,例如将PDF页面保存为JPEG、PNG等常见图像格式。针对每个生成的图像,调用阿里云的文字识别OCR接口,提交图像进行文字识别。确保在请求参数中设置正确的识别类型和其他相关参数。
解析并处理OCR接口返回的识别结果。根据您的需求,提取需要的文本信息或执行进一步的数据处理操作。
需要注意的是,PDF转换为图片时,应确保图像质量高且清晰可见,以获得更准确的文字识别结果。此外,如果PDF文档较大,可能需要考虑分页处理和批量上传的方式,以避免接口调用的限制。
对于阿里云的文字识别OCR服务,目前仅支持上传图片进行文字识别,不直接支持上传PDF文档。您可以将PDF文档转换为图片格式,然后再使用文字识别OCR服务进行文字提取。
以下是将PDF文档转换为图片的一种方法:
使用PDF处理工具:使用第三方的PDF处理工具,如Adobe Acrobat、Foxit PhantomPDF等,将需要识别的PDF文档转换为图片格式(如JPEG、PNG等),通常这些工具都提供了将PDF页面转为图片的选项。
在线转换工具:通过在线的PDF转图片工具,将PDF文档上传并选择将其转换为图片格式。一些在线转换工具如Smallpdf、Zamzar、iLovePDF等都提供PDF转图片的功能,您可以在浏览器中搜索并选择适合您的工具。
编程实现:使用编程语言和相关的库,如Python中的pdf2image库、PyPDF2库等,将PDF文档转换为图片。这样您可以在自己的程序中实现自动的PDF转图片功能。
无论采用哪种方法,一旦将PDF转换为图片格式,就可以将生成的图片上传到阿里云的文字识别OCR服务进行文字提取和识别。