tongchenkeji 发表于:2023-8-22 15:58:410次点击 已关注取消关注 关注 私信 文字识别OCR这种竖着 并且长度不订的表格 识别 是没办法识别吗?[阿里云OCR] 暂停朗读为您朗读 文字识别OCR这种竖着 并且长度不订的表格 识别 是没办法识别吗? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940
魏红斌AM 2023-11-28 3:19:33 1 阿里云表格识别,是阿里云官方自研OCR文字识别产品,支持对多种表格格式(有线表格、条纹表格、无线表格)进行智能文字识别并结构化输出识别结果。阿里云OCR产品基于阿里巴巴达摩院强大的AI技术及海量数据,历经多年沉淀打磨,具有服务稳定、操作简易、实时性高、能力全面等几大优势,可以使用阿里云自定义模板进行调整。
认真学习的heartAM 2023-11-28 3:19:33 2 自定义表格模板是针对固定版式的单页有框线表格表单数据提供的一款定制化产品。用户仅需通过一张模板数据的可视化拖拉拽配置参照字段、识别字段或表头&待识别的列表区域,字段属性等,无需进行数据标注和模型训练,即可实现相同版式数据的自定义结构化识别抽取。经过配置调优的模板识别准确率可达85%以上。文档
小周sirAM 2023-11-28 3:19:33 3 阿里云文字识别OCR服务通常可以识别水平方向上的表格,但对于竖向排列并且长度不固定的表格来说,可能会存在一些识别困难。OCR技术在处理复杂表格时可能会遇到以下问题: 表格结构解析:竖向排列的表格可能使得表格结构的解析更加复杂,因为文字和行之间的边界不再是水平的。这可能导致OCR算法在正确分割和提取表格内容时遇到困难。 单元格内容识别:由于竖向排列的表格布局与传统的水平表格布局不同,OCR算法需要适应不同的文本方向,并正确识别每个单元格中的内容。这可能需要使用特定的算法或模型来处理。 尽管如此,OCR技术在某些情况下仍然可以处理部分竖向表格,并提取其中的文本信息。为了改善竖向表格的识别准确性,您可以尝试以下方法: 预处理图像:对图像进行预处理,例如旋转、调整透视变换等,使表格变为水平方向。这样可以更容易地利用OCR技术进行表格内容的识别。 指定区域识别:如果您知道表格在图像中的位置,可以通过指定特定区域进行识别,以减少干扰并提高识别准确性。 自定义模板:针对特定的竖向表格,您可以尝试创建自定义模板,指定每个单元格的位置和结构,以便更准确地提取表格内容。
三掌柜666AM 2023-11-28 3:19:33 4 楼主你好,阿里云的文字识别OCR可以处理包括表格在内的各种文本,包括竖着的表格。但是,对于长度不固定的表格,OCR可能会出现误差或者无法识别的情况,因为长度不固定的表格往往存在行与行之间的间距不同、列与列之间的宽度不同以及单元格合并等情况,这些都会影响识别结果。 同时,如果表格中的字体、字号、颜色等也与OCR所设定的默认识别范围不同,也可能会影响表格的识别效果。因此,在使用OCR进行表格识别时,需要根据实际情况调整OCR的参数或者对识别结果进行后处理。看一下下面的类型:
圆不溜秋的小猫猫AM 2023-11-28 3:19:33 6 列表型表格部分要用右边表格栏标注的表格标注工具标注的,详情可见https://help.aliyun.com/document_detail/603349.html?spm=a2c4g.603346.0.0.40425530a7Z2xf#c45693bea17cl 此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”
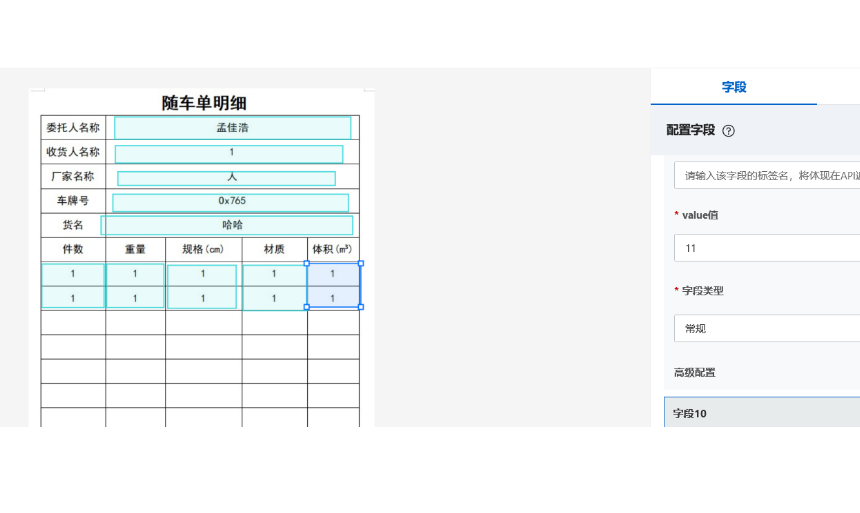
阿里云表格识别,是阿里云官方自研OCR文字识别产品,支持对多种表格格式(有线表格、条纹表格、无线表格)进行智能文字识别并结构化输出识别结果。
阿里云OCR产品基于阿里巴巴达摩院强大的AI技术及海量数据,历经多年沉淀打磨,具有服务稳定、操作简易、实时性高、能力全面等几大优势,可以使用阿里云自定义模板进行调整。
自定义表格模板是针对固定版式的单页有框线表格表单数据提供的一款定制化产品。用户仅需通过一张模板数据的可视化拖拉拽配置参照字段、识别字段或表头&待识别的列表区域,字段属性等,无需进行数据标注和模型训练,即可实现相同版式数据的自定义结构化识别抽取。经过配置调优的模板识别准确率可达85%以上。文档
阿里云文字识别OCR服务通常可以识别水平方向上的表格,但对于竖向排列并且长度不固定的表格来说,可能会存在一些识别困难。OCR技术在处理复杂表格时可能会遇到以下问题:
表格结构解析:竖向排列的表格可能使得表格结构的解析更加复杂,因为文字和行之间的边界不再是水平的。这可能导致OCR算法在正确分割和提取表格内容时遇到困难。
单元格内容识别:由于竖向排列的表格布局与传统的水平表格布局不同,OCR算法需要适应不同的文本方向,并正确识别每个单元格中的内容。这可能需要使用特定的算法或模型来处理。
尽管如此,OCR技术在某些情况下仍然可以处理部分竖向表格,并提取其中的文本信息。为了改善竖向表格的识别准确性,您可以尝试以下方法:
预处理图像:对图像进行预处理,例如旋转、调整透视变换等,使表格变为水平方向。这样可以更容易地利用OCR技术进行表格内容的识别。
指定区域识别:如果您知道表格在图像中的位置,可以通过指定特定区域进行识别,以减少干扰并提高识别准确性。
自定义模板:针对特定的竖向表格,您可以尝试创建自定义模板,指定每个单元格的位置和结构,以便更准确地提取表格内容。
楼主你好,阿里云的文字识别OCR可以处理包括表格在内的各种文本,包括竖着的表格。但是,对于长度不固定的表格,OCR可能会出现误差或者无法识别的情况,因为长度不固定的表格往往存在行与行之间的间距不同、列与列之间的宽度不同以及单元格合并等情况,这些都会影响识别结果。
同时,如果表格中的字体、字号、颜色等也与OCR所设定的默认识别范围不同,也可能会影响表格的识别效果。因此,在使用OCR进行表格识别时,需要根据实际情况调整OCR的参数或者对识别结果进行后处理。看一下下面的类型:
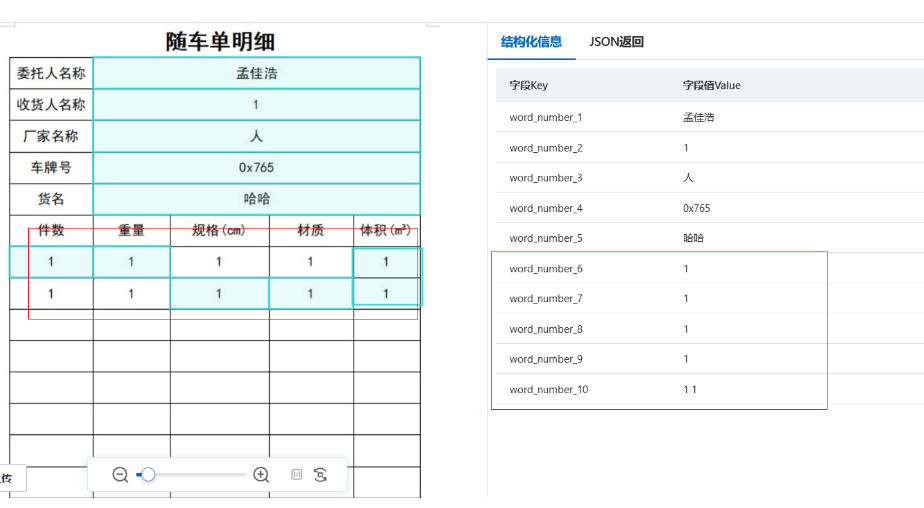
这个情况,建议使用OCR的自定义表格模板。
文档地址:自定义表格模板
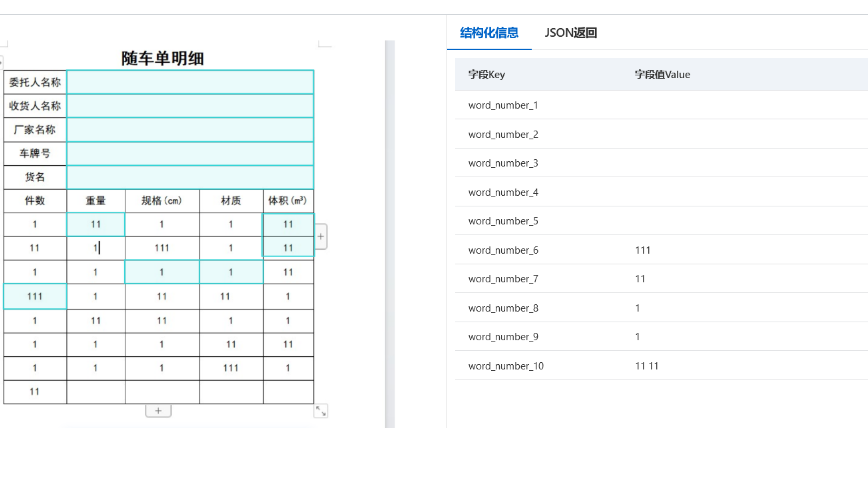
调整模块的时候要注意,框体长度每次都是固定的,不能识别动态的。
列表型表格部分要用右边表格栏标注的表格标注工具标注的,详情可见https://help.aliyun.com/document_detail/603349.html?spm=a2c4g.603346.0.0.40425530a7Z2xf#c45693bea17cl
此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”