文字识别OCR 混贴发票识别中(一图多发票)的情况基于子图坐标在原图中截取图片,请问这个子图坐标是指返回的sliceRect 吗?返回的x0-x3,y0-y3,, 这些个点具体表示什么意思呀(是指切割点(x0,y0),(x1,y1),(x2,y2),(x3,y3))? 截取具体需要用到哪些参数呀?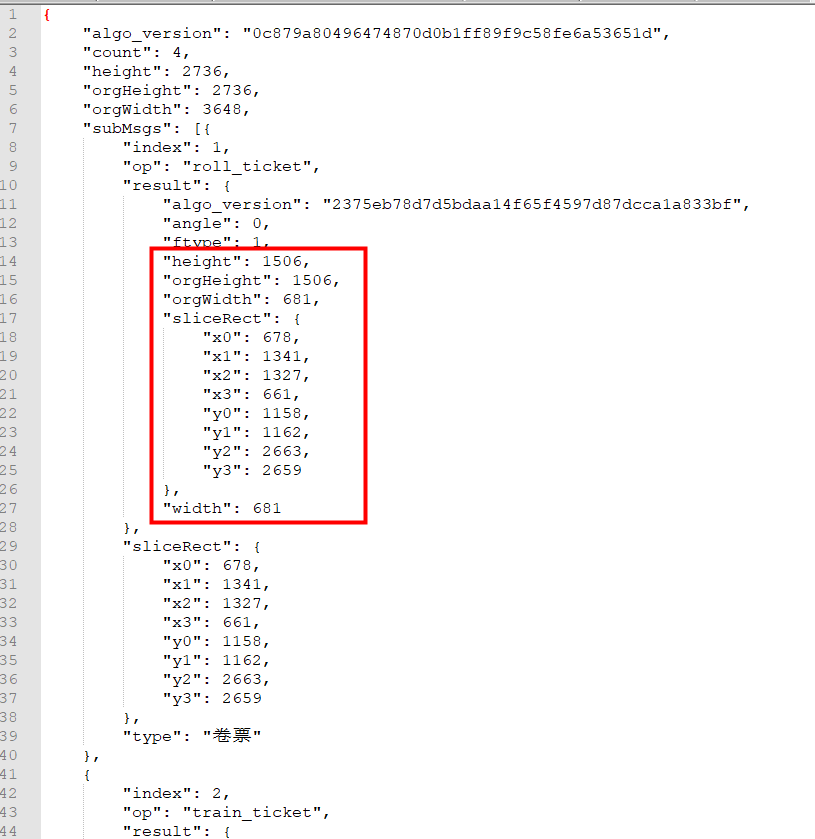

一张这样的图片,只有这一张还勉强出了点内容,
文字识别OCR混贴发票识别中的情况基于子图坐标在原图中截取图片,截取具体需要用到哪些参数呀?[阿里云OCR]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
是的 sliceRect 坐标可以按照 x0y0 x1y1 x2y2 x3y3 作为一个矩形框 表示 在图中的左上、右上、右下、左下。图片子图要保证清晰。
此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”。
文字块的外矩形四个点的坐标按顺时针排列(左上、右上、右下、左下)。当NeedRotate=true时,如果最外层的angle不为0,需要按照angle矫正图片后,坐标才准确。
阿里云全文识别高精版,是阿里云官方自研OCR文字识别产品,智能识别图片所包含的全部字段,集表格识别、旋转识别、生僻字识别等多功能为一体,提供高性价比的多场景文字识别体验。
阿里云OCR产品基于阿里巴巴达摩院强大的AI技术及海量数据,历经多年沉淀打磨,具有服务稳定、操作简易、实时性高、能力全面等几大优势。
楼主你好,是的,子图坐标指的是返回的sliceRect。sliceRect中的x0、y0、x1、y1、x2、y2、x3、y3是四个顶点的坐标,标示切割点(x0,y0),(x1,y1),(x2,y2),(x3,y3)。
在截取图片时,需要使用以下参数:
可以使用以下 Python 代码来做图片截取:
其中,input_image_path是原图的文件路径或URL,output_image_path是处理后的图片的输出路径,slice_rect是子图坐标的四个顶点坐标。
在阿里云文字识别OCR的混贴发票识别中,针对一张图片中存在多个发票的情况,可以使用返回的sliceRect参数来截取每个发票的子图。
具体来说,混贴发票识别返回的sliceRect参数包含了四个坐标点 (x0, y0), (x1, y1), (x2, y2), (x3, y3),它们表示在原图中需要截取的子图的四个角点坐标。这四个坐标点可以描述一个矩形区域,该区域是混贴发票中一个发票的位置。
截取子图时,可以使用这四个坐标点指定的区域作为截取范围,将原图中对应的区域截取出来,以获取单独的发票图像。
截取子图的参数包括:
通过指定对应的坐标点来截取子图,可以获得单独的发票图像进行后续的处理和分析。