tongchenkeji 发表于:2023-9-18 19:57:020次点击 已关注取消关注 关注 私信 各位麻烦问一下,进口报关单,文字识别OCR对于跨页的PDF文档怎么办?[阿里云OCR] 暂停朗读为您朗读 各位麻烦问一下,进口报关单,文字识别OCR对于跨页的PDF文档怎么办?类似这种的 第一页和第二页格式不一样 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940
三掌柜666AM 2023-11-28 3:23:25 1 楼主你好,如果您正在使用阿里云文字识别OCR进行跨页PDF文档的识别,可以将PDF文档拆分为单页PDF文档。然后,您可以使用阿里云文字识别OCR API对每个单页PDF文档进行识别。您也可以使用第三方工具将PDF文档拆分为单页PDF文档,如Adobe Acrobat等。
小周sirAM 2023-11-28 3:23:25 3 对于跨页的PDF文档,文字识别OCR可以采用以下方法处理: 分页处理:首先,将跨页的PDF文档进行分页处理,将每一页单独提取出来。这可以通过使用PDF处理库或工具来实现,例如Python中的PyPDF2库或Adobe Acrobat软件。 单页文字识别:对于每一页单独进行文字识别OCR处理。将每个单独的PDF页面作为输入,应用文字识别OCR模型进行文本提取。这可以通过调用OCR服务的API或使用OCR软件库来实现。 合并结果:将每页识别的文本结果按照原始文档的顺序进行合并。根据文档的结构和布局,可以将识别结果按页码顺序重新组合,以还原原始的跨页文档。 需要注意的是,跨页文档的识别可能会涉及到页眉、页脚、换行等问题,因此在合并结果时可能需要进行一些额外的处理和调整。另外,确保文档的清晰度和质量也是关键,清晰的文档图像有助于提高OCR识别的准确性。 如果应用场景要求更高的准确性和效率,可以考虑使用专门针对跨页文档处理的OCR技术,如长文档信息抽取模型。这些模型可以在处理跨页文档时更好地理解和提取结构化信息。

楼主你好,如果您正在使用阿里云文字识别OCR进行跨页PDF文档的识别,可以将PDF文档拆分为单页PDF文档。然后,您可以使用阿里云文字识别OCR API对每个单页PDF文档进行识别。您也可以使用第三方工具将PDF文档拆分为单页PDF文档,如Adobe Acrobat等。
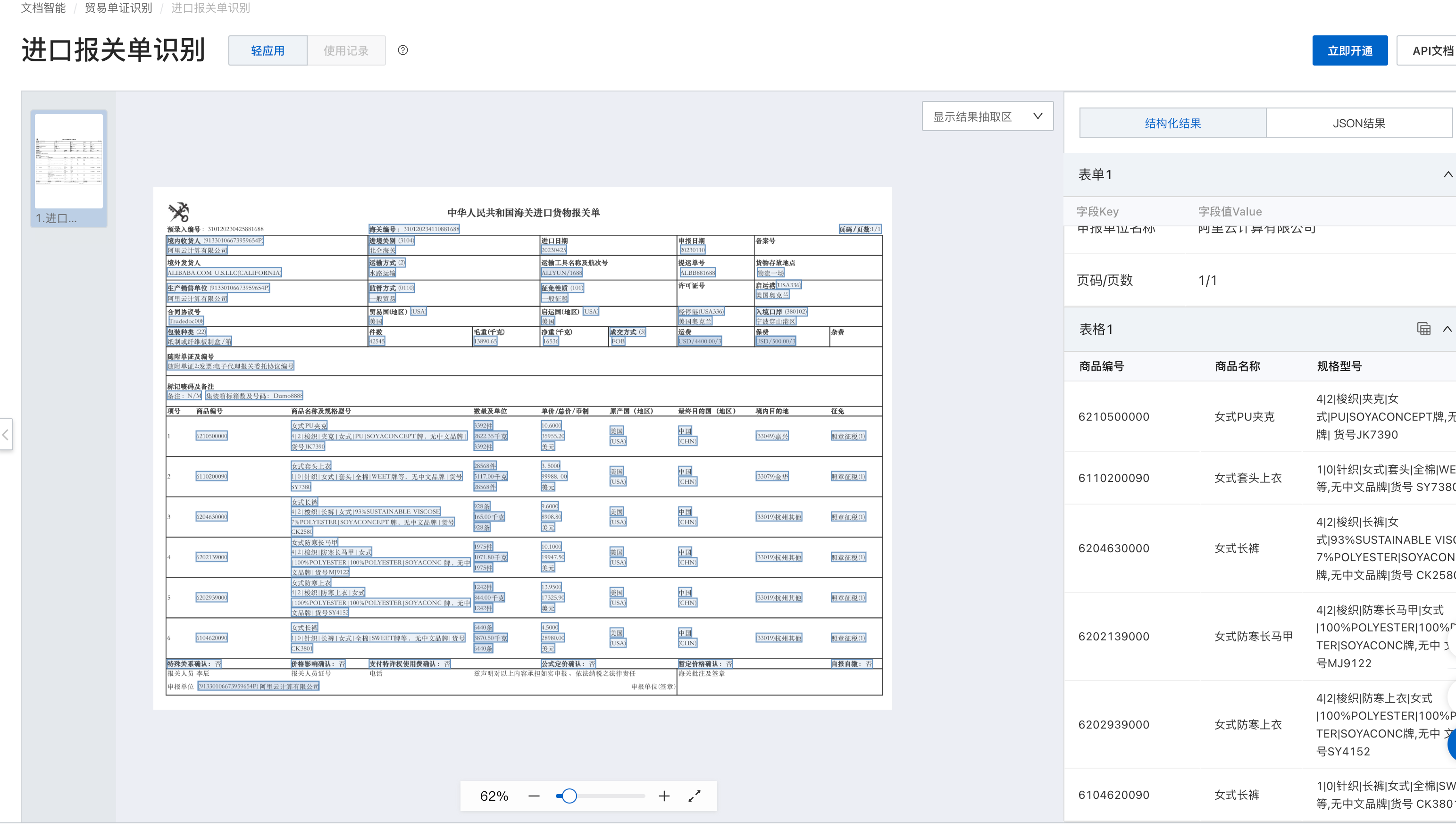
您好,文字识别OCR目前暂时不支持报关单的识别,您可以通过文档智能的进口报关单识别来实现您的业务场景,对于进口报关单识别文档中有具体的要求
对于跨页的PDF文档,文字识别OCR可以采用以下方法处理:
分页处理:首先,将跨页的PDF文档进行分页处理,将每一页单独提取出来。这可以通过使用PDF处理库或工具来实现,例如Python中的PyPDF2库或Adobe Acrobat软件。
单页文字识别:对于每一页单独进行文字识别OCR处理。将每个单独的PDF页面作为输入,应用文字识别OCR模型进行文本提取。这可以通过调用OCR服务的API或使用OCR软件库来实现。
合并结果:将每页识别的文本结果按照原始文档的顺序进行合并。根据文档的结构和布局,可以将识别结果按页码顺序重新组合,以还原原始的跨页文档。
需要注意的是,跨页文档的识别可能会涉及到页眉、页脚、换行等问题,因此在合并结果时可能需要进行一些额外的处理和调整。另外,确保文档的清晰度和质量也是关键,清晰的文档图像有助于提高OCR识别的准确性。
如果应用场景要求更高的准确性和效率,可以考虑使用专门针对跨页文档处理的OCR技术,如长文档信息抽取模型。这些模型可以在处理跨页文档时更好地理解和提取结构化信息。