tongchenkeji 发表于:2023-9-13 19:02:020次点击 已关注取消关注 关注 私信 文字识别OCR还有空格怎么也保留呢?[阿里云OCR] 暂停朗读为您朗读 文字识别OCR还有空格怎么也保留呢?标注的时候空格是有的,但是模型训练完之后体验的时候就都没有空格了 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940
六月的雨在钉钉AM 2023-11-28 3:32:27 1 您好,您可以尝试一下文字识别OCR文档自学习的自定义表格模板,通过一张模板数据的可视化拖拉拽配置参照字段、识别字段或表头&待识别的列表区域,字段属性等,无需进行数据标注和模型训练,即可实现相同版式数据的自定义结构化识别抽取。 具体的操作步骤可以参考文档:文档
三掌柜666AM 2023-11-28 3:32:27 2 楼主你好,阿里云文字识别OCR的识别结果可能会去掉空格。如果您需要保留空格,可以尝试在识别结果中添加空格并重新训练模型。另外,您可以尝试在OCR识别之前使用文本清洗技术,例如移除多余空格或添加缺失空格,以帮助提高OCR的准确性和空格的保留。
Star时光AM 2023-11-28 3:32:27 3 要保留文字识别OCR中的空格,您可以尝试以下方法: 调整OCR参数:某些OCR服务提供商可能具有用于调整识别结果的参数设置。您可以查看相关文档或API参考,了解是否有与空格相关的参数选项。尝试更改参数设置以确保空格被正确识别和保留。 使用特殊字符处理:有些OCR服务会将空格识别为普通字符,而不是保留其作为空格。在处理识别结果时,您可以使用特殊字符处理功能来替换这些字符为实际的空格。例如,您可以将特殊字符替换为Unicode编码中的空格字符(U+0020)。 后处理和规则定义:在进行OCR后,您可以应用后处理步骤来处理识别结果并保留空格。这可以通过使用正则表达式或其他字符串处理技术来实现。您可以编写适当的规则和逻辑来检测和保留空格。 自定义模型训练:对于一些OCR服务,您可能有机会使用自定义模型进行训练。通过提供包含空格样本的训练数据,您可以训练OCR模型以更好地识别和保留空格。这需要更多的工作和资源,但可以提高空格保留的准确性。
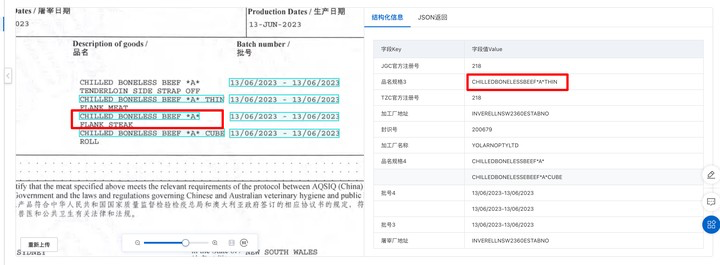
您好,您可以尝试一下文字识别OCR文档自学习的自定义表格模板,通过一张模板数据的可视化拖拉拽配置参照字段、识别字段或表头&待识别的列表区域,字段属性等,无需进行数据标注和模型训练,即可实现相同版式数据的自定义结构化识别抽取。
具体的操作步骤可以参考文档:文档
楼主你好,阿里云文字识别OCR的识别结果可能会去掉空格。如果您需要保留空格,可以尝试在识别结果中添加空格并重新训练模型。另外,您可以尝试在OCR识别之前使用文本清洗技术,例如移除多余空格或添加缺失空格,以帮助提高OCR的准确性和空格的保留。
要保留文字识别OCR中的空格,您可以尝试以下方法:
调整OCR参数:某些OCR服务提供商可能具有用于调整识别结果的参数设置。您可以查看相关文档或API参考,了解是否有与空格相关的参数选项。尝试更改参数设置以确保空格被正确识别和保留。
使用特殊字符处理:有些OCR服务会将空格识别为普通字符,而不是保留其作为空格。在处理识别结果时,您可以使用特殊字符处理功能来替换这些字符为实际的空格。例如,您可以将特殊字符替换为Unicode编码中的空格字符(U+0020)。
后处理和规则定义:在进行OCR后,您可以应用后处理步骤来处理识别结果并保留空格。这可以通过使用正则表达式或其他字符串处理技术来实现。您可以编写适当的规则和逻辑来检测和保留空格。
自定义模型训练:对于一些OCR服务,您可能有机会使用自定义模型进行训练。通过提供包含空格样本的训练数据,您可以训练OCR模型以更好地识别和保留空格。这需要更多的工作和资源,但可以提高空格保留的准确性。
这个用表格模型就可以解决。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”