tongchenkeji 发表于:2023-9-13 19:07:070次点击 已关注取消关注 关注 私信 为什么在训练模型勾选了自动选择十分之一的训练集作为测试集,但文字识别OCR的有效测试集数不显示呢?[阿里云OCR] 暂停朗读为您朗读 为什么在训练模型的时候勾选了自动选择十分之一的训练集作为测试集,但是文字识别OCR这里的有效测试集数不显示呢? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940
玥轩AM 2023-11-28 3:36:19 1 在训练模型时勾选了自动选择十分之一的训练集作为测试集,但是文字识别OCR这里的有效测试集数不显示,可能是因为OCR系统的测试集数量与训练集数量并不是简单的十分之一关系。OCR系统需要根据具体情况选择合适的测试集数量,以确保模型的准确性和稳定性。因此,OCR系统可能会自动选择其他数量的测试集,或者需要手动指定测试集数量。建议您查看OCR系统的文档或者联系技术支持,了解具体情况并进行调整。
三掌柜666AM 2023-11-28 3:36:19 2 楼主你好,可能是因为您的训练集太小而导致的。在使用自动选择十分之一的训练集作为测试集时,如果训练集的大小不足以支持进行有效的测试,那么系统就无法显示有效测试集的数量。建议您扩大训练集的大小或使用其他测试方法来确保模型的准确性。
六月的雨在钉钉AM 2023-11-28 3:36:19 3 您好,文字识别OCR文档自学习这里的有效测试集未展示并不影响训练数据集的训练效果,训练集数量达到一定的数量后对于模版识别准确率的提升是一致的。
小周sirAM 2023-11-28 3:36:19 4 在训练模型时,勾选了自动选择十分之一的训练集作为测试集,是为了评估模型的性能和准确率。但是,在OCR文字识别服务中,有效测试集数并不是根据训练时的测试集大小来计算的,而是根据您在OCR服务中设置的测试集大小来计算的。
Star时光AM 2023-11-28 3:36:19 6 在文字识别OCR中,自动选择训练集的十分之一作为测试集是一个常见的做法来评估模型的性能。然而,阿里云OCR服务并不直接提供显示有效测试集数的功能。 在OCR服务中,模型的性能和准确度是通过针对多个真实场景下的数据进行训练和调优来确定的。在训练过程中,使用的数据集包含了大量的样本和标注信息,以帮助模型学习和识别各种类型的文本。 由于OCR涉及到广泛的应用领域和多样化的场景,有效测试集的具体定义可能会因具体的任务和需求而有所不同。即使没有直接显示有效测试集数,但您仍然可以通过以下方式来评估OCR模型的性能: 使用真实场景下的数据进行测试:将真实的图片或扫描件输入OCR服务,观察模型在各种情况下的识别效果。评估模型是否能够准确识别文本,并根据您的需求提取所需的信息。 手动创建测试集:为了更系统地评估OCR模型的性能,您可以手动创建一个专门用于测试的数据集。该数据集应包含不同类型、不同难度和不同场景下的文本图像,以全面评估模型的性能。 定期监测和迭代:OCR模型的性能是一个动态过程,随着您的应用场景和需求的变化,需要持续评估和改进。定期监测模型的准确度,并根据实际反馈和问题进行调整和改进。
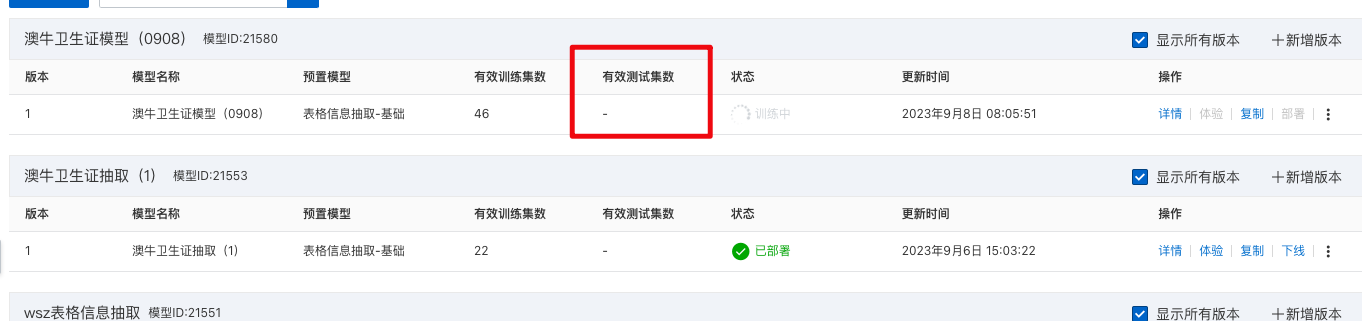
在训练模型时勾选了自动选择十分之一的训练集作为测试集,但是文字识别OCR这里的有效测试集数不显示,可能是因为OCR系统的测试集数量与训练集数量并不是简单的十分之一关系。OCR系统需要根据具体情况选择合适的测试集数量,以确保模型的准确性和稳定性。因此,OCR系统可能会自动选择其他数量的测试集,或者需要手动指定测试集数量。建议您查看OCR系统的文档或者联系技术支持,了解具体情况并进行调整。
楼主你好,可能是因为您的训练集太小而导致的。在使用自动选择十分之一的训练集作为测试集时,如果训练集的大小不足以支持进行有效的测试,那么系统就无法显示有效测试集的数量。建议您扩大训练集的大小或使用其他测试方法来确保模型的准确性。
您好,文字识别OCR文档自学习这里的有效测试集未展示并不影响训练数据集的训练效果,训练集数量达到一定的数量后对于模版识别准确率的提升是一致的。
在训练模型时,勾选了自动选择十分之一的训练集作为测试集,是为了评估模型的性能和准确率。但是,在OCR文字识别服务中,有效测试集数并不是根据训练时的测试集大小来计算的,而是根据您在OCR服务中设置的测试集大小来计算的。
这个对后续的训练和评测没有影响的,这个展示问题我们后续优化下哈。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”
在文字识别OCR中,自动选择训练集的十分之一作为测试集是一个常见的做法来评估模型的性能。然而,阿里云OCR服务并不直接提供显示有效测试集数的功能。
在OCR服务中,模型的性能和准确度是通过针对多个真实场景下的数据进行训练和调优来确定的。在训练过程中,使用的数据集包含了大量的样本和标注信息,以帮助模型学习和识别各种类型的文本。
由于OCR涉及到广泛的应用领域和多样化的场景,有效测试集的具体定义可能会因具体的任务和需求而有所不同。即使没有直接显示有效测试集数,但您仍然可以通过以下方式来评估OCR模型的性能:
使用真实场景下的数据进行测试:将真实的图片或扫描件输入OCR服务,观察模型在各种情况下的识别效果。评估模型是否能够准确识别文本,并根据您的需求提取所需的信息。
手动创建测试集:为了更系统地评估OCR模型的性能,您可以手动创建一个专门用于测试的数据集。该数据集应包含不同类型、不同难度和不同场景下的文本图像,以全面评估模型的性能。
定期监测和迭代:OCR模型的性能是一个动态过程,随着您的应用场景和需求的变化,需要持续评估和改进。定期监测模型的准确度,并根据实际反馈和问题进行调整和改进。