tongchenkeji 发表于:2023-7-4 19:51:050次点击 已关注取消关注 关注 私信 ocr我部署后测试使用,报错了,是需要授权吗?[阿里云OCR] 暂停朗读为您朗读 问题1:ocr我部署后测试使用,报错了,是需要授权吗? 问题2: 改了以后报这个错 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940# 视觉智能开放平台3859
魏红斌AM 2023-11-28 3:40:06 1 如果您在部署OCR后测试时遇到“Message inference unknow error model request error”错误消息,可能是因为您的OCR软件需要授权才能使用。这是因为OCR软件通常需要访问专业的OCR模型和算法,这些模型和算法通常需要受到保护,因此需要授权才能使用。 您可以尝试以下方法来解决这个问题: 获取授权:如果您没有获得授权,您可以联系OCR软件的供应商或开发者,以获得授权。通常,您需要提供您的软件许可证号或其他身份验证信息,以便获得授权。 更新OCR软件:如果您已经获得了授权,但仍然遇到“Message inference unknow error model request error”错误消息,可能是因为您的OCR软件版本太旧,无法支持新的模型和算法。您可以尝试更新OCR软件,以使用最新的模型和算法。 使用其他OCR软件:如果您无法获得授权或更新OCR软件,您可以尝试使用其他OCR软件。有些OCR软件是开源的,不需要授权,或者提供免费试用版或免费版,您可以尝试使用这些软件。
六月的雨在钉钉AM 2023-11-28 3:40:06 2 回答1:这个直接按照在线调试给出的错误提示给对应的RAM账号授权即可; 回答2:应该是缺少必要参数导致接口调用报错,建议参考官方文档参数配置进行操作:文档
算精通AM 2023-11-28 3:40:06 3 缺少必要的参数。 OCR相关API的文档推荐: 文字识别(OCR)API:该API支持识别身份证、银行卡、驾驶证、行驶证、营业执照、通用文字等多种类型的图片和文档。您可以使用该API将图片或文档中的文字内容转换为可编辑的文本格式,并且支持自定义模板和识别结果的后处理。 文档链接:https://help.aliyun.com/document_detail/155645.html 印刷体文字识别(OCR)API:该API专门针对印刷体文字进行识别和提取,支持多种语言和字体,包括中文、英文、数字、符号等。您可以使用该API将印刷体文字转换为可编辑的文本格式,并且支持多种输出格式和识别参数。 文档链接:https://help.aliyun.com/document_detail/155648.html 手写体文字识别(OCR)API:该API专门针对手写体文字进行识别和提取,支持多种语言和字体,包括中文、英文、数字、符号等。您可以使用该API将手写体文字转换为可编辑的文本格式,并且支持多种输出格式和识别参数。 文档链接:https://help.aliyun.com/document_detail/155647.html
xin在这AM 2023-11-28 3:40:06 4 回答1:是的.使用base64 字段BinaryToText设成true 回答2:再试一下,此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群
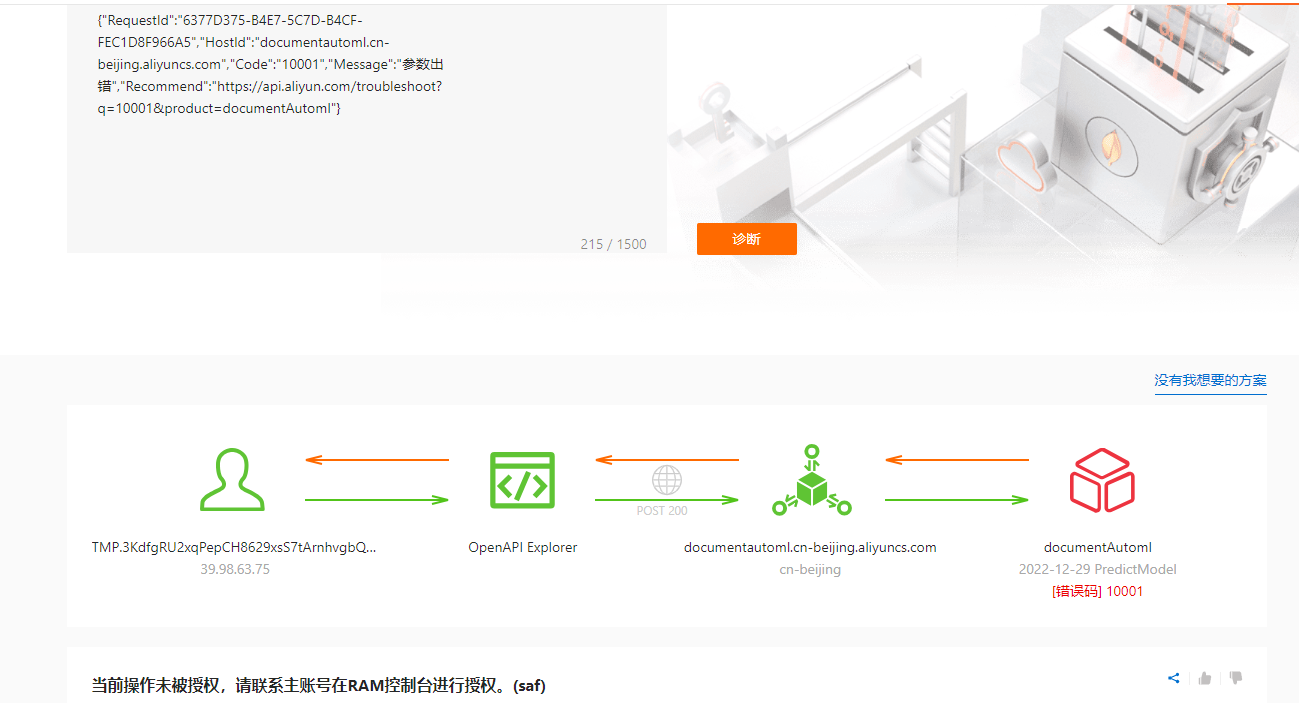 问题2:
问题2: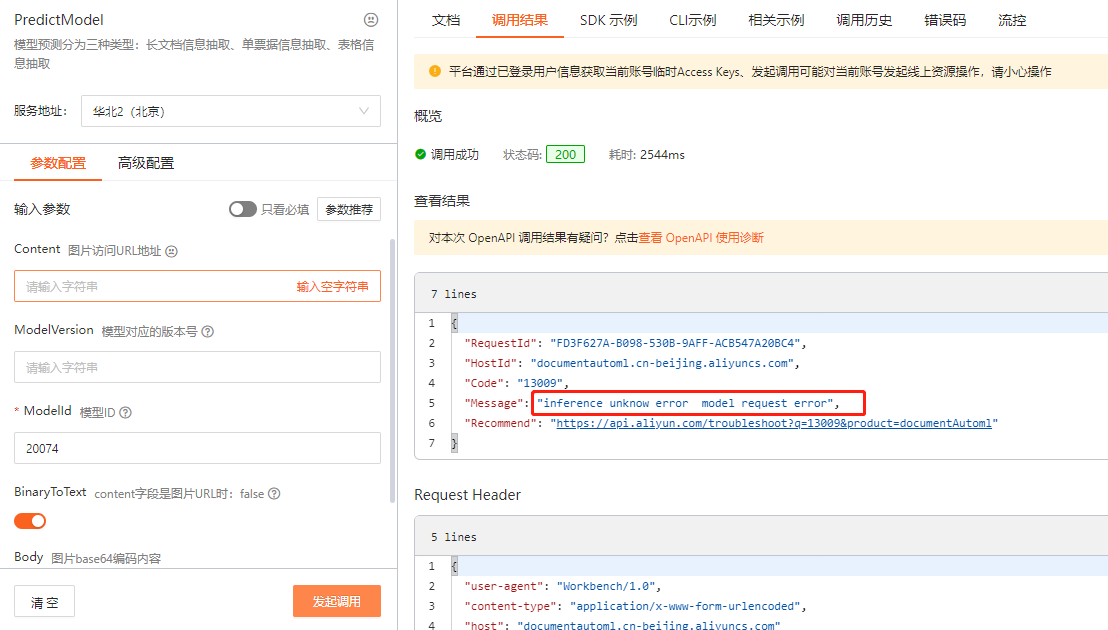 改了以后报这个错 问题2: 改了以后报这个错
改了以后报这个错 问题2: 改了以后报这个错
如果您在部署OCR后测试时遇到“Message inference unknow error model request error”错误消息,可能是因为您的OCR软件需要授权才能使用。这是因为OCR软件通常需要访问专业的OCR模型和算法,这些模型和算法通常需要受到保护,因此需要授权才能使用。 您可以尝试以下方法来解决这个问题:
获取授权:如果您没有获得授权,您可以联系OCR软件的供应商或开发者,以获得授权。通常,您需要提供您的软件许可证号或其他身份验证信息,以便获得授权。 更新OCR软件:如果您已经获得了授权,但仍然遇到“Message inference unknow error model request error”错误消息,可能是因为您的OCR软件版本太旧,无法支持新的模型和算法。您可以尝试更新OCR软件,以使用最新的模型和算法。 使用其他OCR软件:如果您无法获得授权或更新OCR软件,您可以尝试使用其他OCR软件。有些OCR软件是开源的,不需要授权,或者提供免费试用版或免费版,您可以尝试使用这些软件。
回答1:这个直接按照在线调试给出的错误提示给对应的RAM账号授权即可; 回答2:应该是缺少必要参数导致接口调用报错,建议参考官方文档参数配置进行操作:文档
缺少必要的参数。
OCR相关API的文档推荐:
文字识别(OCR)API:该API支持识别身份证、银行卡、驾驶证、行驶证、营业执照、通用文字等多种类型的图片和文档。您可以使用该API将图片或文档中的文字内容转换为可编辑的文本格式,并且支持自定义模板和识别结果的后处理。 文档链接:https://help.aliyun.com/document_detail/155645.html
印刷体文字识别(OCR)API:该API专门针对印刷体文字进行识别和提取,支持多种语言和字体,包括中文、英文、数字、符号等。您可以使用该API将印刷体文字转换为可编辑的文本格式,并且支持多种输出格式和识别参数。 文档链接:https://help.aliyun.com/document_detail/155648.html
手写体文字识别(OCR)API:该API专门针对手写体文字进行识别和提取,支持多种语言和字体,包括中文、英文、数字、符号等。您可以使用该API将手写体文字转换为可编辑的文本格式,并且支持多种输出格式和识别参数。 文档链接:https://help.aliyun.com/document_detail/155647.html
回答1:是的.使用base64 字段BinaryToText设成true 回答2:再试一下,此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群