tongchenkeji 发表于:2023-8-1 12:47:490次点击 已关注取消关注 关注 私信 文字识别OCR这个长文档信息抽取主要有什么用呀?[阿里云OCR] 暂停朗读为您朗读 文字识别OCR这个长文档信息抽取主要有什么用呀?这些证卡都有固定的接口了,要什么字段可以选择性的抓不就行了? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940
三掌柜666AM 2023-11-28 3:47:42 1 楼主你好,阿里云文字识别OCR长文档信息抽取功能可以自动识别文档中的各类结构化数据,并将其转换为计算机可识别的格式,方便后续处理和分析。相比于手动抽取,这种方式更加高效、准确、可靠,可以大大提高工作效率。 在证卡等领域,虽然有固定的接口,但是不同的证卡要素字段可能有所不同,而且如果需要识别的证卡数量较多,手动抓取信息的工作量会非常大。使用OCR长文档信息抽取功能可以自动识别各类证卡中的要素字段,包括姓名、性别、出生日期、证件号码、有效期等等,大大减轻人工工作量,提高数据抽取的准确性和可靠性。 此外,OCR长文档信息抽取功能还可以应用在各种场景中,如企业合同、金融报表、医疗记录等等,可以自动提取出各类关键信息,方便后续数据分析和处理。
wljslmzAM 2023-11-28 3:47:42 2 阿里云文字识别OCR的长文档信息抽取功能主要用于从大段的文本中提取结构化信息,方便后续的数据处理和分析。具体而言,长文档信息抽取可以帮助您实现以下功能: 自动化数据抽取:通过OCR技术和自然语言处理技术,自动从长文档中提取所需的字段信息,无需手动逐一查找和录入,提高数据处理的效率。 数据标准化:对于从不同来源获取的长文档,可能存在格式和表达方式的差异。长文档信息抽取可以将这些信息进行标准化,提取出统一的结构化字段,使数据更易于比较和分析。 数据挖掘和分析:通过长文档信息抽取,可以将文本数据转化为结构化的数据,方便进行数据挖掘、分析和建模。您可以利用提取出的字段信息进行统计分析、关键词提取、文本分类等操作,以便从文本中获取有价值的信息。 对于证卡等有固定接口的情况,您选择性地抓取指定字段是可以的。但是在某些场景下,文本的排版、格式可能会有变化,或者需要从较长的文本片段中提取多个字段,这时候长文档信息抽取功能就能发挥作用。它可以帮助您从长篇文本中提取出预定义的关键信息,而无需手动编写复杂的规则或进行多次抓取。
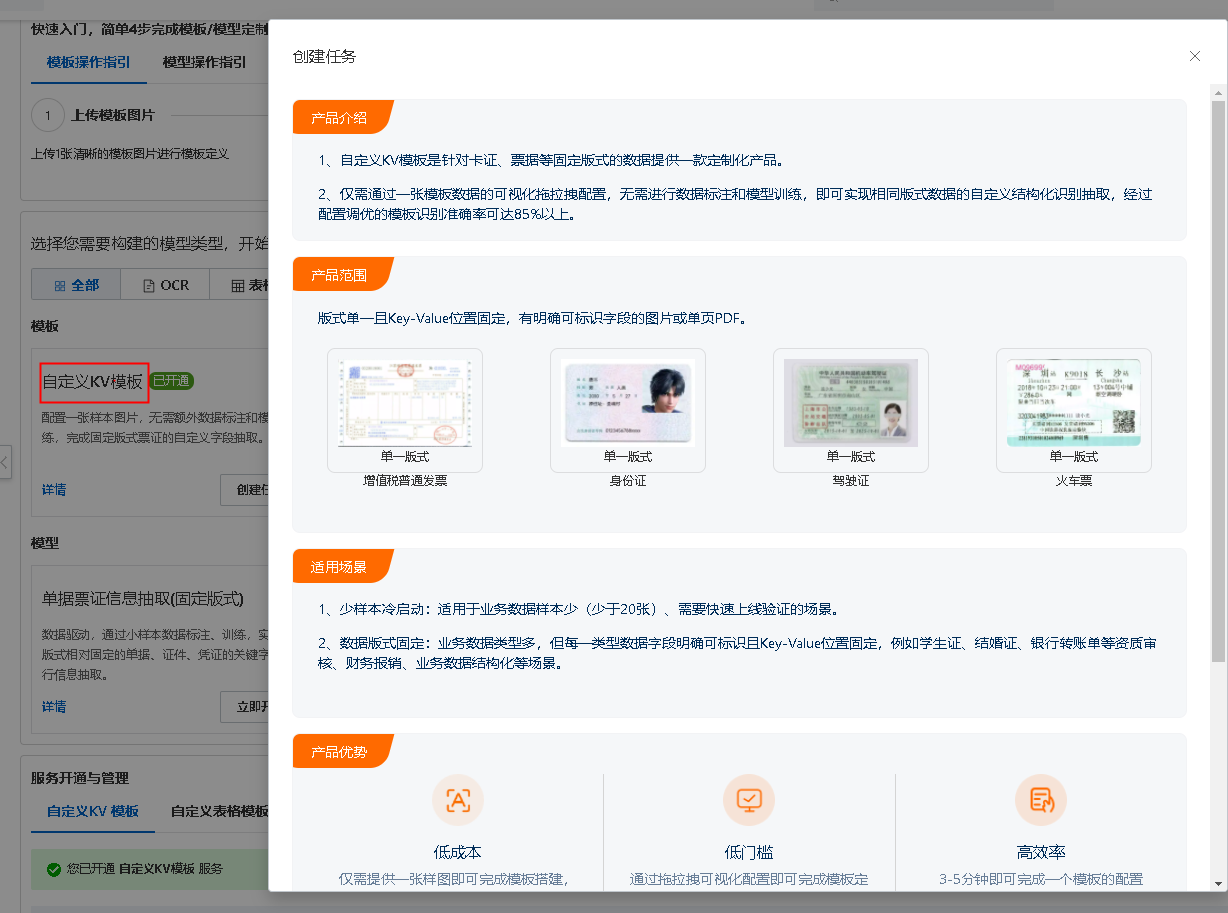
六月的雨在钉钉AM 2023-11-28 3:47:42 3 您好,文字识别OCR文档自学习中的长文档信息抽取按字面理解就是对于比较长的文档的识别效率识别效果上都比较好,通常就是常见的合同、标书、论文、证明等这些文字内容页码比较多的文档,详细的应用场景可以参考官方文档如图 当然也可以选择具体场景的文字识别接口,比如通用文字识别,只是这样的话就没有通过文档自学习训练识别的效果好了。
算精通AM 2023-11-28 3:47:42 4 长文档信息抽取是文字识别OCR技术的一个应用场景,主要用于从大型文档中自动抽取出有价值的信息,例如表格、图表、关键词、实体等。长文档信息抽取的主要用途包括: 自动化文档处理:长文档信息抽取可以帮助用户自动化地处理大量文档,例如从大型合同、报告、简历等中提取出关键信息,以提高工作效率和准确性。 数据分析和挖掘:长文档信息抽取可以帮助用户从大量文档中提取出关键词、实体、图表等信息,以支持数据分析和挖掘的工作。 智能搜索:长文档信息抽取可以帮助用户快速搜索和定位文档中的关键信息,例如搜索某个关键词、表格、图表等,以提高信息检索的效率和准确性。 信息管理和归档:长文档信息抽取可以帮助用户对大量文档进行分类、归档和管理,例如根据文档中的关键词、实体等信息进行分类和归档,以提高信息管理的效率和准确性。
Star时光AM 2023-11-28 3:47:42 5 文字识别OCR的长文档信息抽取功能主要用于处理长篇文档的自动化信息提取和分析。它可以将大量的文本数据转换为结构化的信息,从而帮助用户更高效地管理和利用文档中的内容。 以下是长文档信息抽取的几个主要用途: 数据提取:长文档信息抽取可以从大规模的文档中自动提取出需要的数据,例如姓名、地址、电话号码、日期等。这样可以节省人工手动提取的时间和精力。 文本分类:长文档信息抽取可以自动对长篇文档进行分类,将其归入特定的类别或主题。通过文本分类,可以更快速地进行文档检索、排序和组织。 关键字提取:该功能能够从长文档中提取关键字或关键短语,帮助用户了解文档的主题、重点和核心内容。关键字提取有助于快速浏览和汇总文档的关键信息。 摘要生成:长文档信息抽取可以根据文档的内容自动生成简洁的摘要。这样可以快速了解文档的要点和概要,避免阅读整个文档的时间消耗。 信息搜索和挖掘:通过对长文档进行自动化信息抽取,可以建立起一个结构化的文本数据库。这使得用户能够更便捷地搜索、查询和挖掘文档中的特定信息。 总之,长文档信息抽取功能能够帮助用户快速处理和分析大量文本数据,提取有用的信息并将其转化为可用的形式。这为企业、研究机构和个人用户提供了更高效利用文档的方法,并能够支持各种应用场景,如智能文档管理、知识发现、信息检索等。
凌云CloudAM 2023-11-28 3:47:42 7 我个人觉得长文档信息抽取适用于一些扫描件、PDF文件等,可以快速、准确地将图片中的文字转化为可编辑和可搜索的文本。 像一些文档、报表、报告这类文字较多且没有固定格式的图片。
小周sirAM 2023-11-28 3:47:42 8 文字识别OCR的长文档信息抽取可以提供以下主要功能和用途: 自动化数据提取: 长文档信息抽取可以自动从大量的文档中提取需要的字段和信息,减少人工处理的工作量。这对于处理大规模的文档、表格、报告等非结构化数据特别有用。 数据整合和分析: 通过抽取长文档中的特定字段,您可以将这些数据整合到其他系统或数据库中,以进行进一步的分析、挖掘和应用。这有助于实现数据驱动的决策和业务流程优化。 实时监控和警报: 抽取长文档中的重要字段,如监控报告或合同条款,可以帮助您实时监测关键信息的变化,并触发相应的警报或通知。这有助于快速响应和处理重要事件。 自然语言处理和理解: 长文档信息抽取可以与其他自然语言处理技术结合使用,如文本分类、命名实体识别等。这种结合可以帮助你更好地理解文档内容,进行情感分析、话题建模、知识图谱构建等任务。 搜索和索引: 抽取长文档中的关键字段,如标题、作者、日期等,可以帮助您建立文档的索引和搜索功能。这使得用户可以更快速地找到相关信息。
圆不溜秋的小猫猫AM 2023-11-28 3:47:42 9 比如毕业证、结婚证、海员证、运输证、内部发票等OCR原子能力欠缺的证件/发票 就可以用KV模版。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”
楼主你好,阿里云文字识别OCR长文档信息抽取功能可以自动识别文档中的各类结构化数据,并将其转换为计算机可识别的格式,方便后续处理和分析。相比于手动抽取,这种方式更加高效、准确、可靠,可以大大提高工作效率。
在证卡等领域,虽然有固定的接口,但是不同的证卡要素字段可能有所不同,而且如果需要识别的证卡数量较多,手动抓取信息的工作量会非常大。使用OCR长文档信息抽取功能可以自动识别各类证卡中的要素字段,包括姓名、性别、出生日期、证件号码、有效期等等,大大减轻人工工作量,提高数据抽取的准确性和可靠性。
此外,OCR长文档信息抽取功能还可以应用在各种场景中,如企业合同、金融报表、医疗记录等等,可以自动提取出各类关键信息,方便后续数据分析和处理。
阿里云文字识别OCR的长文档信息抽取功能主要用于从大段的文本中提取结构化信息,方便后续的数据处理和分析。具体而言,长文档信息抽取可以帮助您实现以下功能:
自动化数据抽取:通过OCR技术和自然语言处理技术,自动从长文档中提取所需的字段信息,无需手动逐一查找和录入,提高数据处理的效率。
数据标准化:对于从不同来源获取的长文档,可能存在格式和表达方式的差异。长文档信息抽取可以将这些信息进行标准化,提取出统一的结构化字段,使数据更易于比较和分析。
数据挖掘和分析:通过长文档信息抽取,可以将文本数据转化为结构化的数据,方便进行数据挖掘、分析和建模。您可以利用提取出的字段信息进行统计分析、关键词提取、文本分类等操作,以便从文本中获取有价值的信息。
对于证卡等有固定接口的情况,您选择性地抓取指定字段是可以的。但是在某些场景下,文本的排版、格式可能会有变化,或者需要从较长的文本片段中提取多个字段,这时候长文档信息抽取功能就能发挥作用。它可以帮助您从长篇文本中提取出预定义的关键信息,而无需手动编写复杂的规则或进行多次抓取。
您好,文字识别OCR文档自学习中的长文档信息抽取按字面理解就是对于比较长的文档的识别效率识别效果上都比较好,通常就是常见的合同、标书、论文、证明等这些文字内容页码比较多的文档,详细的应用场景可以参考官方文档如图
当然也可以选择具体场景的文字识别接口,比如通用文字识别,只是这样的话就没有通过文档自学习训练识别的效果好了。
长文档信息抽取是文字识别OCR技术的一个应用场景,主要用于从大型文档中自动抽取出有价值的信息,例如表格、图表、关键词、实体等。长文档信息抽取的主要用途包括:
自动化文档处理:长文档信息抽取可以帮助用户自动化地处理大量文档,例如从大型合同、报告、简历等中提取出关键信息,以提高工作效率和准确性。
数据分析和挖掘:长文档信息抽取可以帮助用户从大量文档中提取出关键词、实体、图表等信息,以支持数据分析和挖掘的工作。
智能搜索:长文档信息抽取可以帮助用户快速搜索和定位文档中的关键信息,例如搜索某个关键词、表格、图表等,以提高信息检索的效率和准确性。
信息管理和归档:长文档信息抽取可以帮助用户对大量文档进行分类、归档和管理,例如根据文档中的关键词、实体等信息进行分类和归档,以提高信息管理的效率和准确性。
文字识别OCR的长文档信息抽取功能主要用于处理长篇文档的自动化信息提取和分析。它可以将大量的文本数据转换为结构化的信息,从而帮助用户更高效地管理和利用文档中的内容。
以下是长文档信息抽取的几个主要用途:
数据提取:长文档信息抽取可以从大规模的文档中自动提取出需要的数据,例如姓名、地址、电话号码、日期等。这样可以节省人工手动提取的时间和精力。
文本分类:长文档信息抽取可以自动对长篇文档进行分类,将其归入特定的类别或主题。通过文本分类,可以更快速地进行文档检索、排序和组织。
关键字提取:该功能能够从长文档中提取关键字或关键短语,帮助用户了解文档的主题、重点和核心内容。关键字提取有助于快速浏览和汇总文档的关键信息。
摘要生成:长文档信息抽取可以根据文档的内容自动生成简洁的摘要。这样可以快速了解文档的要点和概要,避免阅读整个文档的时间消耗。
信息搜索和挖掘:通过对长文档进行自动化信息抽取,可以建立起一个结构化的文本数据库。这使得用户能够更便捷地搜索、查询和挖掘文档中的特定信息。
总之,长文档信息抽取功能能够帮助用户快速处理和分析大量文本数据,提取有用的信息并将其转化为可用的形式。这为企业、研究机构和个人用户提供了更高效利用文档的方法,并能够支持各种应用场景,如智能文档管理、知识发现、信息检索等。
您好, OCR自学习长文档信息抽取功能只抽取文档结构化信息,不支持还原文档样式。更多使用功能问题请联系我们。
我个人觉得长文档信息抽取适用于一些扫描件、PDF文件等,可以快速、准确地将图片中的文字转化为可编辑和可搜索的文本。
像一些文档、报表、报告这类文字较多且没有固定格式的图片。
文字识别OCR的长文档信息抽取可以提供以下主要功能和用途:
自动化数据提取: 长文档信息抽取可以自动从大量的文档中提取需要的字段和信息,减少人工处理的工作量。这对于处理大规模的文档、表格、报告等非结构化数据特别有用。
数据整合和分析: 通过抽取长文档中的特定字段,您可以将这些数据整合到其他系统或数据库中,以进行进一步的分析、挖掘和应用。这有助于实现数据驱动的决策和业务流程优化。
实时监控和警报: 抽取长文档中的重要字段,如监控报告或合同条款,可以帮助您实时监测关键信息的变化,并触发相应的警报或通知。这有助于快速响应和处理重要事件。
自然语言处理和理解: 长文档信息抽取可以与其他自然语言处理技术结合使用,如文本分类、命名实体识别等。这种结合可以帮助你更好地理解文档内容,进行情感分析、话题建模、知识图谱构建等任务。
搜索和索引: 抽取长文档中的关键字段,如标题、作者、日期等,可以帮助您建立文档的索引和搜索功能。这使得用户可以更快速地找到相关信息。
比如毕业证、结婚证、海员证、运输证、内部发票等OCR原子能力欠缺的证件/发票 就可以用KV模版。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”