tongchenkeji 发表于:2023-8-1 12:46:030次点击 已关注取消关注 关注 私信 文字识别OCR表格抽取,训练报错了,怎么解决?[阿里云OCR] 暂停朗读为您朗读 文字识别OCR表格抽取,训练报错了,怎么解决? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940
三掌柜666AM 2023-11-28 3:48:14 1 楼主你好,如果阿里云文字识别OCR表格抽取的训练报错了,可以尝试以下解决方案: 检查训练模型的参数设置是否正确; 检查训练数据是否符合标准,需要保证数据的质量和数量; 检查训练环境是否正常,比如GPU、驱动、内存和硬盘等,需要确保环境全部正常; 重新运行训练,如果还是报错,可以联系技术支持寻求帮助。 另外,训练的过程中也要注意监控训练过程,比如查看日志文件,了解训练的具体情况,帮助诊断和解决问题。
算精通AM 2023-11-28 3:48:14 2 可以尝试以下几种解决方法: 检查数据集:检查数据集的质量和准确性,确保数据集中的标注正确,并尽可能扩大数据集的规模。 调整算法参数:根据实际情况调整算法参数,例如增大学习率、增加批量大小、增加迭代次数等,以提高训练效果。 检查环境配置:检查训练环境的配置,确保环境配置正确,并且具备足够的计算资源。 尝试其他模型:如果使用的模型无法训练成功,可以尝试使用其他的OCR表格抽取模型,以提高训练效果。 参考文档和论坛:可以参考OCR表格抽取技术的相关文档、论文和论坛,以获取更多的训练技巧和经验,以提高训练效果。
Star时光AM 2023-11-28 3:48:14 3 如果你在训练文字识别OCR的表格抽取模型时遇到报错,可以尝试以下方法来解决问题: 检查输入数据:确保你提供的表格图片符合OCR服务要求的格式,并且清晰度高、没有模糊、反光或遮挡。还要确保表格图片中的表格结构明确、字体清晰可见。 数据预处理:对于表格图片,可以尝试进行一些图像预处理操作,如去噪、平滑、二值化等,以优化图片质量。这有助于提升OCR模型的训练效果。 增加训练数据量:增加更多的具有多样性的训练数据,包括不同类型的表格、字体和布局,可以提升模型的泛化能力和准确性。 调整训练参数:尝试调整OCR模型的训练参数,例如学习率、批大小、迭代次数等,以找到更好的训练结果。根据具体情况,进行反复尝试并优化参数设置。 查阅文档或社区支持:参考OCR服务的官方文档、帮助中心或社区论坛,查找与你遇到的错误相关的解决方案。可能会有其他用户遇到过类似的问题,并且已经给出了相应的解决方法。 联系技术支持:如果以上方法仍无法解决问题,建议联系OCR服务的技术支持团队。他们将能够提供专业的帮助和指导,帮助你解决训练报错的具体问题。
小周sirAM 2023-11-28 3:48:14 5 当文字识别OCR表格抽取训练报错时,您可以尝试以下方法来解决问题: 检查数据质量: 首先,请确保您的训练数据集质量良好。训练数据应该包含多样化的表格样式和布局,并且表格中的文本清晰可读。如果数据质量较差或存在噪音,可能会导致训练报错。 增加训练数据: 如果训练报错,可能是因为您的训练数据不足以覆盖所有可能的表格样式和情况。尝试增加更多的训练数据,特别是那些具有复杂布局或特殊格式的表格,以提高训练模型的泛化性能。 调整模型参数: 您可以尝试调整文字识别OCR模型的参数,如学习率、批次大小、网络结构等。不同的参数设置可能会对训练结果产生影响,尝试不同的组合来优化训练过程和性能。 使用预训练模型: 考虑使用已经预训练的OCR模型作为起点,然后在您的特定数据集上进行微调。这样可以减少训练时间和资源消耗,并提供更好的初始模型性能。 查看错误信息: 仔细阅读训练报错的错误信息,通常会提供一些有关问题所在的线索。根据错误信息调整相关参数或修复数据中的问题。 寻求专业支持: 如果您尝试了上述方法仍然无法解决问题,建议向OCR服务供应商或相关技术社区寻求专业支持。他们可以提供更具体的指导和帮助,以解决训练报错问题。
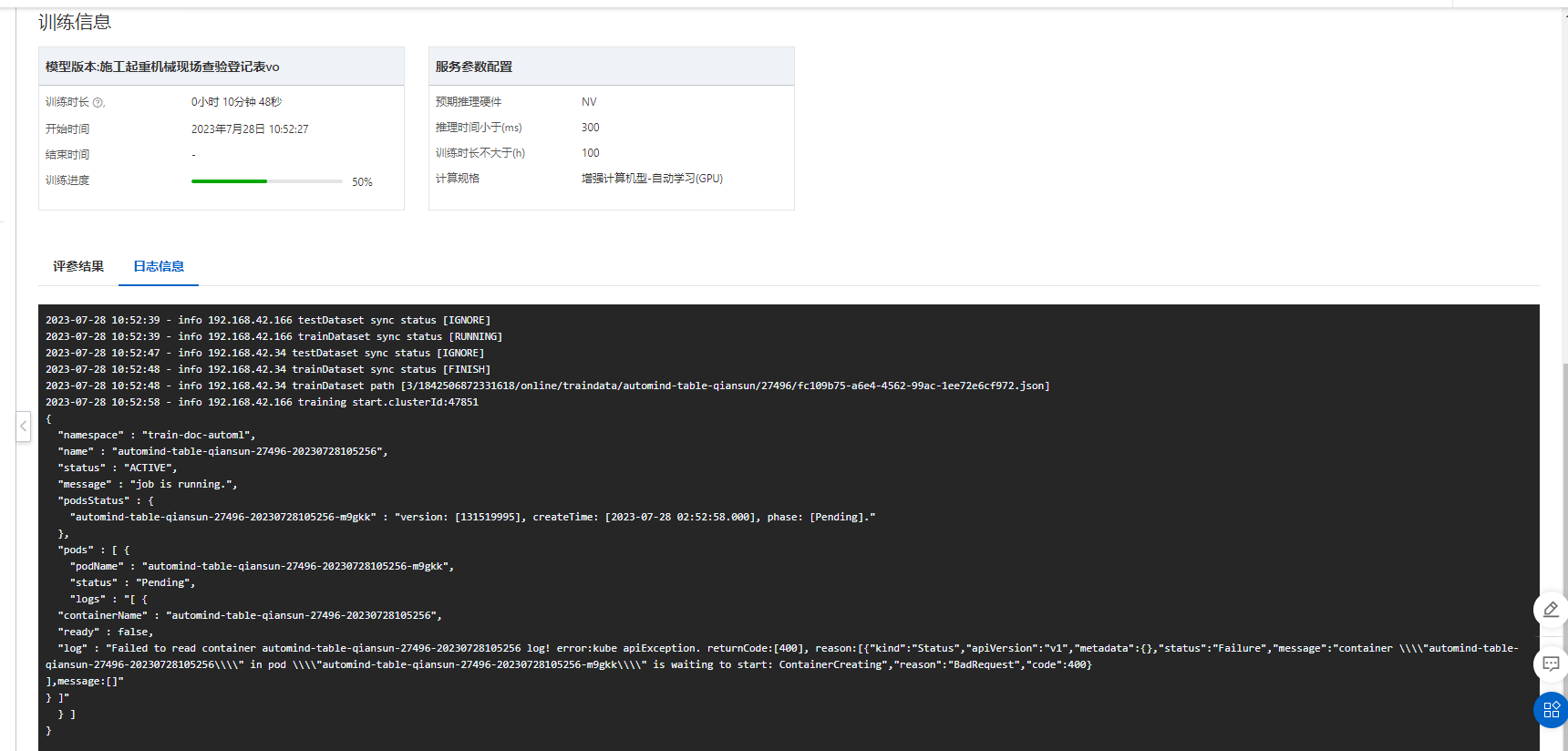
楼主你好,如果阿里云文字识别OCR表格抽取的训练报错了,可以尝试以下解决方案:
另外,训练的过程中也要注意监控训练过程,比如查看日志文件,了解训练的具体情况,帮助诊断和解决问题。
可以尝试以下几种解决方法:
检查数据集:检查数据集的质量和准确性,确保数据集中的标注正确,并尽可能扩大数据集的规模。
调整算法参数:根据实际情况调整算法参数,例如增大学习率、增加批量大小、增加迭代次数等,以提高训练效果。
检查环境配置:检查训练环境的配置,确保环境配置正确,并且具备足够的计算资源。
尝试其他模型:如果使用的模型无法训练成功,可以尝试使用其他的OCR表格抽取模型,以提高训练效果。
参考文档和论坛:可以参考OCR表格抽取技术的相关文档、论文和论坛,以获取更多的训练技巧和经验,以提高训练效果。
如果你在训练文字识别OCR的表格抽取模型时遇到报错,可以尝试以下方法来解决问题:
检查输入数据:确保你提供的表格图片符合OCR服务要求的格式,并且清晰度高、没有模糊、反光或遮挡。还要确保表格图片中的表格结构明确、字体清晰可见。
数据预处理:对于表格图片,可以尝试进行一些图像预处理操作,如去噪、平滑、二值化等,以优化图片质量。这有助于提升OCR模型的训练效果。
增加训练数据量:增加更多的具有多样性的训练数据,包括不同类型的表格、字体和布局,可以提升模型的泛化能力和准确性。
调整训练参数:尝试调整OCR模型的训练参数,例如学习率、批大小、迭代次数等,以找到更好的训练结果。根据具体情况,进行反复尝试并优化参数设置。
查阅文档或社区支持:参考OCR服务的官方文档、帮助中心或社区论坛,查找与你遇到的错误相关的解决方案。可能会有其他用户遇到过类似的问题,并且已经给出了相应的解决方法。
联系技术支持:如果以上方法仍无法解决问题,建议联系OCR服务的技术支持团队。他们将能够提供专业的帮助和指导,帮助你解决训练报错的具体问题。
您好, OCR自学习长文档信息抽取功能只抽取文档结构化信息,不支持还原文档样式。更多使用功能问题请联系我们。
当文字识别OCR表格抽取训练报错时,您可以尝试以下方法来解决问题:
检查数据质量: 首先,请确保您的训练数据集质量良好。训练数据应该包含多样化的表格样式和布局,并且表格中的文本清晰可读。如果数据质量较差或存在噪音,可能会导致训练报错。
增加训练数据: 如果训练报错,可能是因为您的训练数据不足以覆盖所有可能的表格样式和情况。尝试增加更多的训练数据,特别是那些具有复杂布局或特殊格式的表格,以提高训练模型的泛化性能。
调整模型参数: 您可以尝试调整文字识别OCR模型的参数,如学习率、批次大小、网络结构等。不同的参数设置可能会对训练结果产生影响,尝试不同的组合来优化训练过程和性能。
使用预训练模型: 考虑使用已经预训练的OCR模型作为起点,然后在您的特定数据集上进行微调。这样可以减少训练时间和资源消耗,并提供更好的初始模型性能。
查看错误信息: 仔细阅读训练报错的错误信息,通常会提供一些有关问题所在的线索。根据错误信息调整相关参数或修复数据中的问题。
寻求专业支持: 如果您尝试了上述方法仍然无法解决问题,建议向OCR服务供应商或相关技术社区寻求专业支持。他们可以提供更具体的指导和帮助,以解决训练报错问题。
已经在训练了 那个提示可以忽略 以status为准。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”