tongchenkeji 发表于:2023-11-30 13:39:540次点击 已关注取消关注 关注 私信 DataWorks准实时整库全增量,报错,这个启动时间在哪里配置?[阿里云] 暂停朗读为您朗读 DataWorks准实时整库全增量,报错,这个启动时间在哪里配置? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 阿里云# DataWorks3343# 大数据开发治理平台 DataWorks3946
小周sirAM 2023-12-3 11:40:58 1 在 DataWorks 中配置准实时整库全增量任务时,报错可能与启动时间的设置有关。通常情况下,你可以在数据集成模块中进行相关配置。 为了找到并配置启动时间,请按照以下步骤操作: 登录 DataWorks:使用你的阿里云账号登录到 DataWorks 平台。 导航到数据集成:在左侧菜单栏中,选择“数据开发”> “数据集成”,进入数据集成页面。 选择任务类型:在数据集成页面上,点击右上角的“新建任务”按钮,在弹出的下拉菜单中选择“整库全量同步”或“整库周期性增量同步”任务类型。 配置源和目标数据库信息:根据提示,输入源数据库和目标数据库的相关信息,包括数据库地址、端口、用户名、密码以及要同步的表等。 设置调度参数:在任务配置界面中,滚动到下方的“调度参数”部分。在这里,你可以设置启动时间(开始执行的时间)以及其他调度相关的选项。 如果你的任务是按小时调度的,可以设置具体的小时数作为启动时间,例如 0 0/1 * * * ? 表示每小时的第 0 分钟开始执行。 如果你的任务是按天调度的,可以设置每天的某个时刻作为启动时间,例如 0 0 0 * * ? 表示每天的午夜 12 点开始执行。 保存和提交任务:检查所有的配置是否正确无误后,点击底部的“保存”按钮保存你的任务配置,然后点击“发布”按钮将其提交到生产环境。
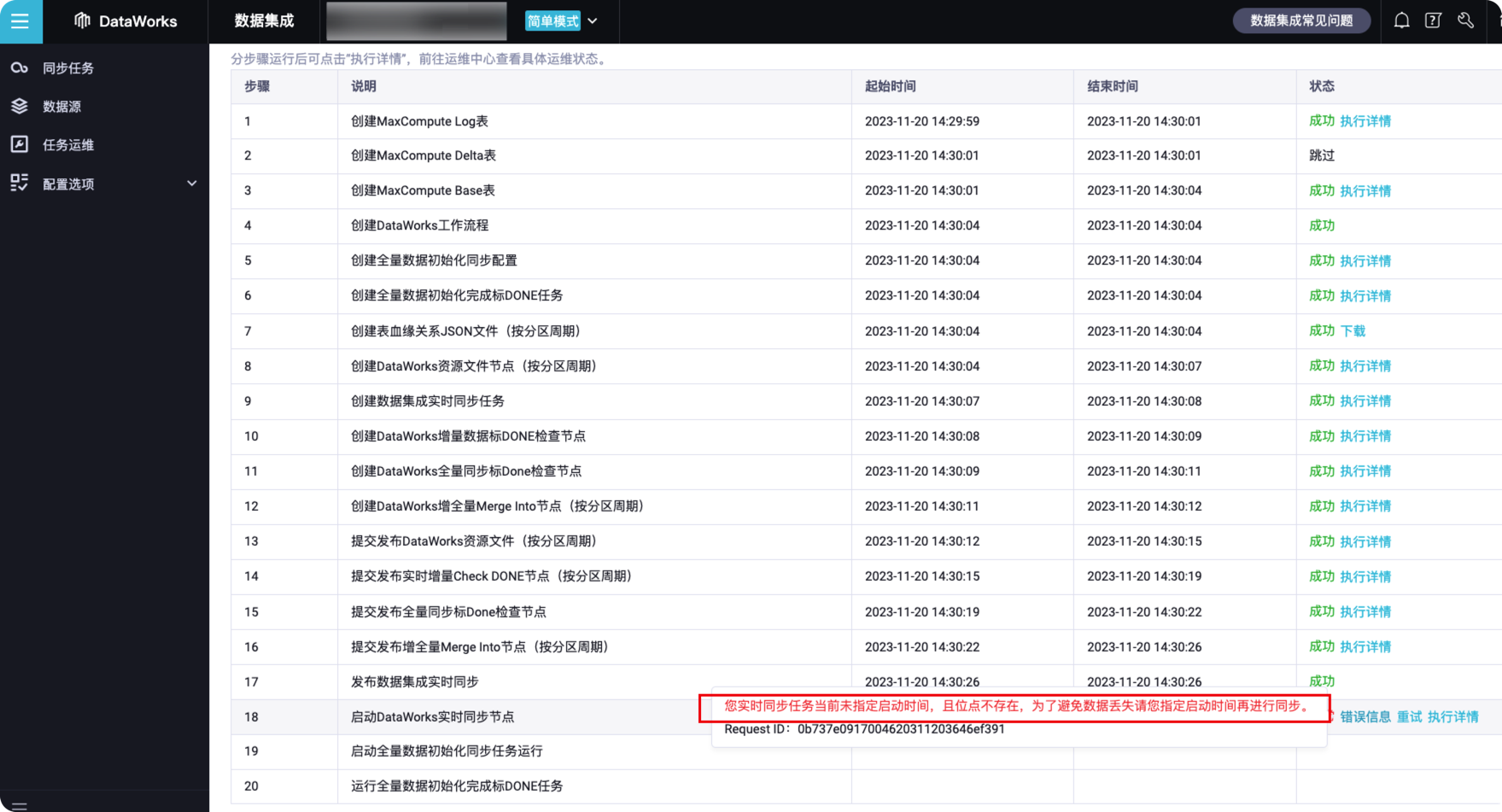
xin在这AM 2023-12-3 11:40:58 2 with recuresive 不能使用,不能做递归查询,任务是刚创建首次启动的吗,启动时间是默认记录的边界位点 这里应该不好手动选择 需要到运维中心启动的时候才可以指定 手动指定位点可能会导致中间有部分时间的位点数据丢失 建议解决方案任务整体强制重跑试一下 离线任务也会重新刷一遍,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在 DataWorks 中配置准实时整库全增量任务时,报错可能与启动时间的设置有关。通常情况下,你可以在数据集成模块中进行相关配置。
为了找到并配置启动时间,请按照以下步骤操作:
设置调度参数:在任务配置界面中,滚动到下方的“调度参数”部分。在这里,你可以设置启动时间(开始执行的时间)以及其他调度相关的选项。
0 0/1 * * * ?表示每小时的第 0 分钟开始执行。0 0 0 * * ?表示每天的午夜 12 点开始执行。保存和提交任务:检查所有的配置是否正确无误后,点击底部的“保存”按钮保存你的任务配置,然后点击“发布”按钮将其提交到生产环境。
with recuresive 不能使用,不能做递归查询,任务是刚创建首次启动的吗,启动时间是默认记录的边界位点 这里应该不好手动选择 需要到运维中心启动的时候才可以指定 手动指定位点可能会导致中间有部分时间的位点数据丢失 建议解决方案任务整体强制重跑试一下 离线任务也会重新刷一遍,此回答整理自钉群“DataWorks交流群(答疑@机器人)”