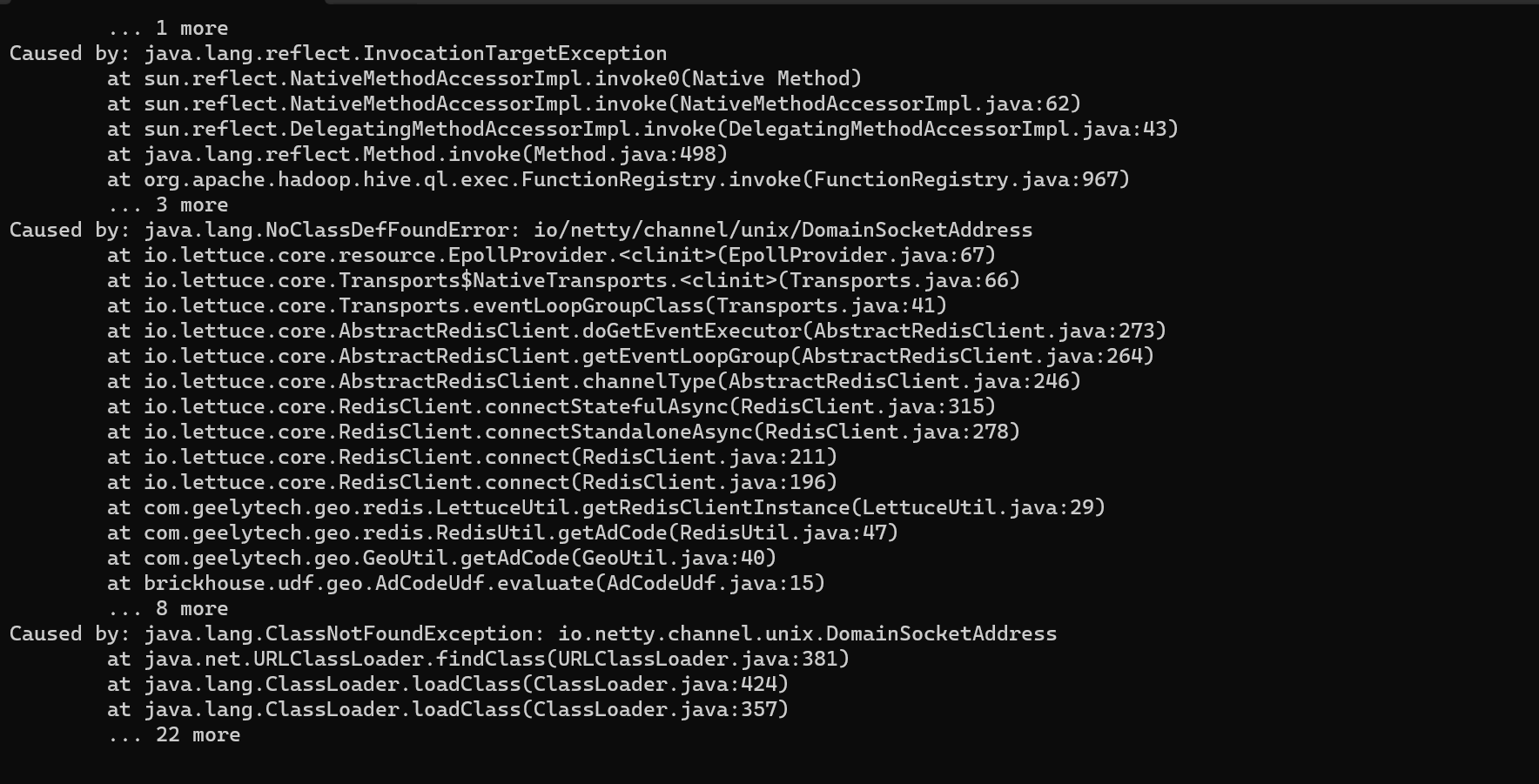
大数据计算MaxCompute dataworks底座是cdh的hive,现在将这个环境的hive的udf函数上传到mc新环境,但是在mc新环境上不可用,这个是什么原因呢?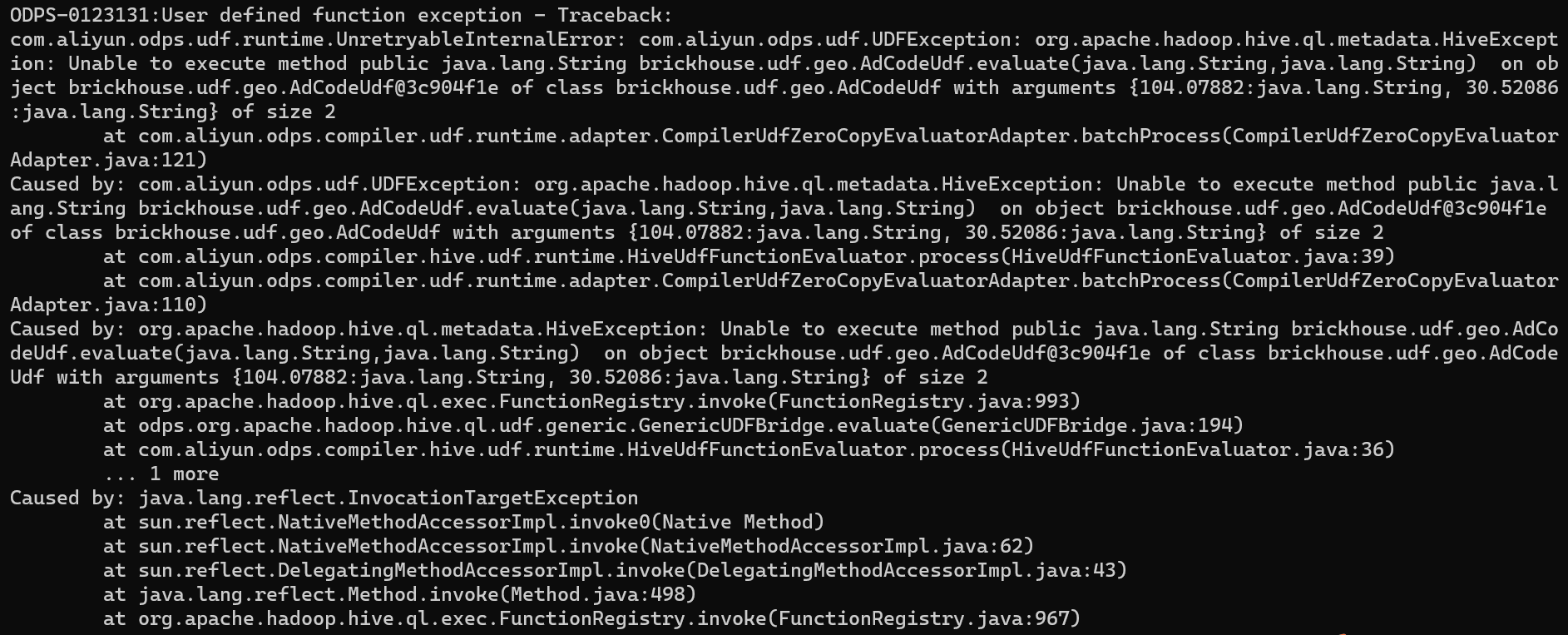
大数据计算MaxCompute dataworks底座是cdh的hive,这个是什么原因呢?[阿里云]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
![]()
大数据计算MaxCompute dataworks底座是cdh的hive,现在将这个环境的hive的udf函数上传到mc新环境,但是在mc新环境上不可用,这个是什么原因呢?
hive跟MaxCompute底层也不是完全兼容的。你先加上hive兼容看能不能跑。set odps.sql.hive.compatible=true;
看报错是缺少类。 MaxCompute的函数是需要上传 jar和注册函数。
需要检查一下jar中的类是不是都有。
https://help.aliyun.com/zh/maxcompute/user-guide/function-operations?spm=a2c4g.11186623.0.i12,此回答整理自钉群“MaxCompute开发者社区2群”
出现Hive UDF函数在MaxCompute新环境上不可用的原因可能是以下几种情况:
语法差异:MaxCompute和Hive虽然都属于大数据计算领域,但其语法和函数库有一些差异。如果您直接将Hive UDF函数上传到MaxCompute环境中,可能会遇到语法兼容性问题或函数不存在的情况。您需要对Hive UDF函数进行适当的修改和调整,以满足MaxCompute的语法要求。
编译依赖:Hive UDF函数通常需要通过编译生成对应的二进制文件(JAR包等),这些文件包含了具体的实现代码。在MaxCompute环境中,UDF函数也需要经过编译并部署到相应的资源中。您需要确保正确编译Hive UDF函数,并将生成的二进制文件上传到MaxCompute环境中。
函数依赖和兼容性:Hive UDF函数可能依赖于特定的底层库或第三方组件。在将函数迁移到MaxCompute环境时,需要确保相关的依赖项也在目标环境中存在,并且与MaxCompute兼容。
函数注册和权限:在MaxCompute中,需要显式地将UDF函数注册到函数列表中才能使用。您需要确认是否正确注册了Hive UDF函数,并为相应的用户或角色授予执行UDF函数的权限。
请注意,MaxCompute提供了自己的UDF函数库,并且与Hive并不完全兼容。在将Hive UDF函数迁移到MaxCompute时,您可能需要重新实现这些函数,以适应MaxCompute的环境和要求。