tongchenkeji 发表于:2023-11-30 11:48:580次点击 已关注取消关注 关注 私信 大数据计算MaxCompute这两个ID为什么会被判断为同一个ID?[阿里云] 暂停朗读为您朗读 大数据计算MaxCompute这两个ID为什么会被判断为同一个ID?我看了下如果where条件换成字符串类型,就是正确的’ 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 阿里云# MaxCompute2748# 云原生大数据计算服务 MaxCompute3255# 分布式计算2827# 大数据1264
xin在这AM 2023-12-3 11:42:30 1 那可能是隐式转换导致的。我测试一下,转成了double。 加cast 强转一下,或者数据类型要正确。 ,此回答整理自钉群“MaxCompute开发者社区2群”
小周sirAM 2023-12-3 11:42:30 2 在大数据计算中,两个ID可能被判断为同一个ID的原因有多种。这里列举一些常见的原因: 哈希冲突: 如果使用哈希函数对多个字段生成唯一标识符(如雪花算法),由于哈希函数的输出范围有限,不同的输入可能会产生相同的输出,这就是哈希冲突。 为了减少哈希冲突的可能性,可以尝试使用更好的哈希函数或者组合更多的字段。 编码问题: 如果数据存储或传输过程中存在编码转换的问题,可能导致原本不同的字符串被误判为相同。 确保在处理字符串时使用的字符集和编码方式一致。 空格、换行或其他特殊字符: 在比较字符串时,如果忽视了空格、换行或其他特殊字符的存在,可能会导致误判。 使用适当的字符串清理函数来去除多余的空白字符。 精度丢失: 对于浮点数或者其他类型的数据,可能存在精度丢失的情况,导致看似不同的值实际上在计算机内部表示是相同的。 使用更高的精度或者使用其他类型的数据(如整数)来避免精度损失。 逻辑错误: 在编写代码时出现逻辑错误,例如错误地将两个不同的变量视为相同。 检查并修复代码中的逻辑错误。 外部系统影响: 如果这两个ID是从外部系统获取的,可能是这些系统之间的同步或映射关系存在问题。 联系外部系统的维护人员以解决问题。
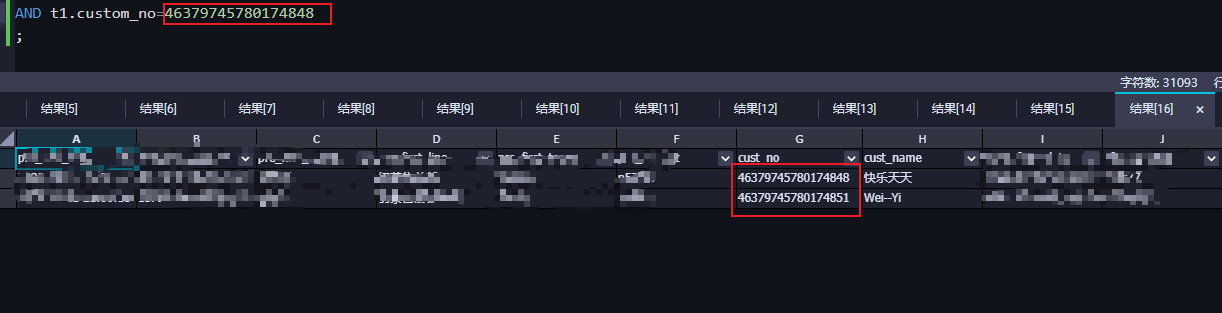
那可能是隐式转换导致的。我测试一下,转成了double。
加cast 强转一下,或者数据类型要正确。 ,此回答整理自钉群“MaxCompute开发者社区2群”
在大数据计算中,两个ID可能被判断为同一个ID的原因有多种。这里列举一些常见的原因:
哈希冲突:
编码问题:
空格、换行或其他特殊字符:
精度丢失:
逻辑错误:
外部系统影响: