相同的两个程序一个在云flink产品上部署时 Managed Memory 直接打满,另一个在emr自建的yarn上跑 Managed Memory 几乎 没有占用,这是怎么回事?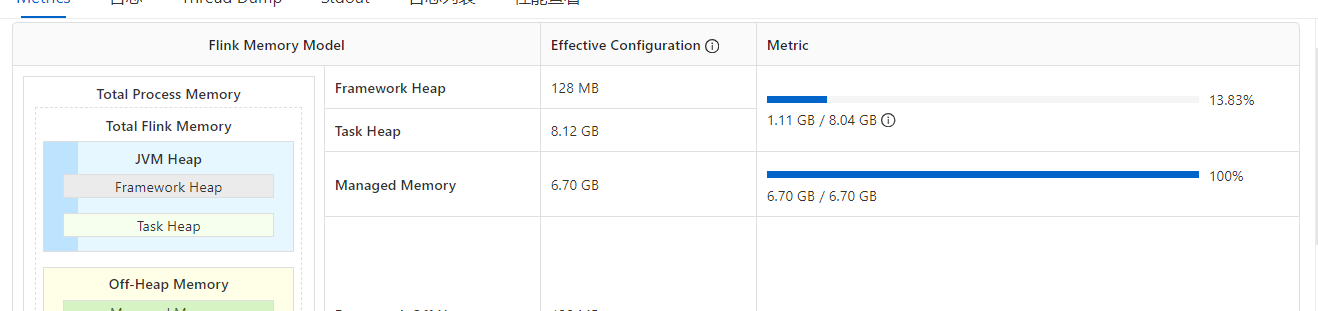
相同的程序一个在云flink产品部署时Managed Memory打满,另一个几乎没有占用,为什么?[阿里云]
「点点赞赏,手留余香」
还没有人赞赏,快来当第一个赞赏的人吧!
![]()
相同的两个程序一个在云flink产品上部署时 Managed Memory 直接打满,另一个在emr自建的yarn上跑 Managed Memory 几乎 没有占用,这是怎么回事?
为了解决这个问题,建议检查和比较两个环境中的Flink配置,特别是与内存管理相关的配置。同时,监控程序运行时的实际工作负载和资源使用情况,以识别可能导致差异的原因。如有必要,可以调整配置以优化内存使用。
当两个相同的程序在不同的环境(云上的Flink产品和自建的YARN上的EMR)中运行时,出现Managed Memory使用差异的原因可能有几个方面:
配置差异:云上Flink产品和自建YARN上的EMR可能有不同的默认配置或者针对特定环境优化的配置。这可能包括内存管理、垃圾回收策略、任务调度等。特别是Managed Memory的配置和分配策略可能不同。
资源分配策略:云服务通常提供了更加严格和高效的资源分配机制,以确保每个任务获得足够的资源。因此,在云上Flink产品中,系统可能会为Managed Memory分配更多资源以保证性能,而在自建的YARN环境中,资源分配可能更加保守。
工作负载差异:即使程序相同,运行环境和数据的不同可能导致实际的工作负载有所差异。例如,输入数据的大小、处理速度、数据序列化和反序列化等方面的差异都可能影响Managed Memory的使用。
环境优化和调整:云服务提供商通常会对他们的产品进行优化,以提高性能和资源利用率。这些优化可能包括内存管理方面的调整,导致与自建环境中相同程序的内存使用表现不同。
版本和依赖差异:不同环境中使用的Flink版本或依赖库可能不同,这也可能影响内存管理和使用。
在部署和运行相同的Flink程序时,Managed Memory 的使用情况可能会因为不同的部署环境而有所差异。下面是一些可能导致这种情况发生的原因:
配置差异:云Flink产品和自建的YARN集群可能具有不同的默认配置和资源分配策略。云Flink产品可能更倾向于使用更多的Managed Memory来提供更好的性能和稳定性,因此在部署时可能会分配更多的Managed Memory。而在自建的YARN集群上,您可以根据需求进行更灵活的资源配置。
资源限制:云Flink产品和自建的YARN集群可能设置了不同的资源限制。云Flink产品可能会限制Managed Memory的总量,并根据作业的需求进行动态调整。而在自建的YARN集群上,您可以通过配置文件或命令行参数来设置Managed Memory的大小。
并行度差异:Flink程序的并行度也可能影响Managed Memory的使用情况。如果两个程序的并行度设置不同,那么它们对Managed Memory的需求也会有所区别。较高的并行度可能需要更多的内存来存储状态和缓冲区,导致Managed Memory占用更多的资源。
数据量和计算复杂度:如果两个程序的输入数据量或计算复杂度不同,那么它们对Managed Memory的需求也会有所不同。较大的数据量或更复杂的计算可能需要更多的Managed Memory来处理和存储中间状态。
要解决这个问题,您可以尝试以下方法:
managed memory 一启动Gemini就会把所有分配给它的managed都claim过去,所以这上面是看不出实际用量的。此回答整理自钉群“实时计算Flink产品交流群”