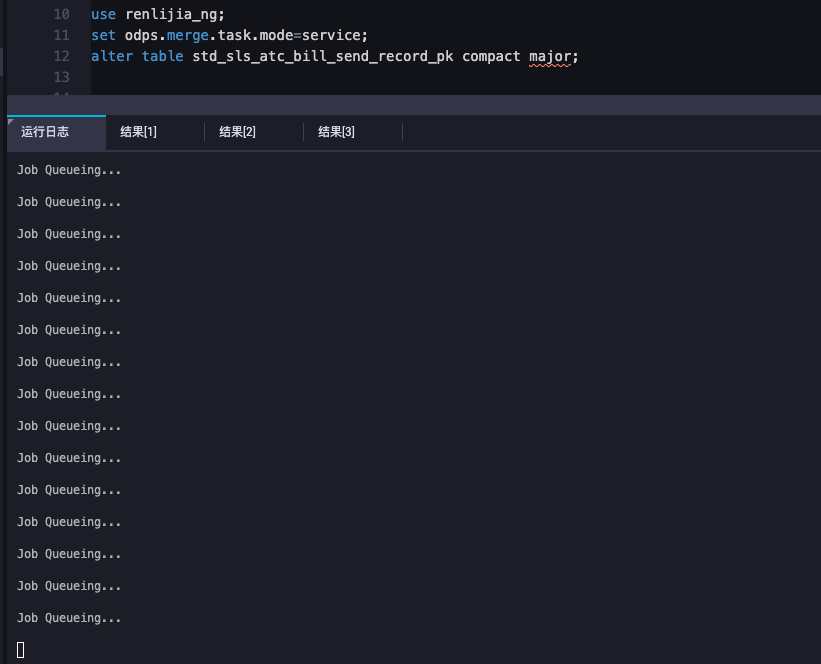
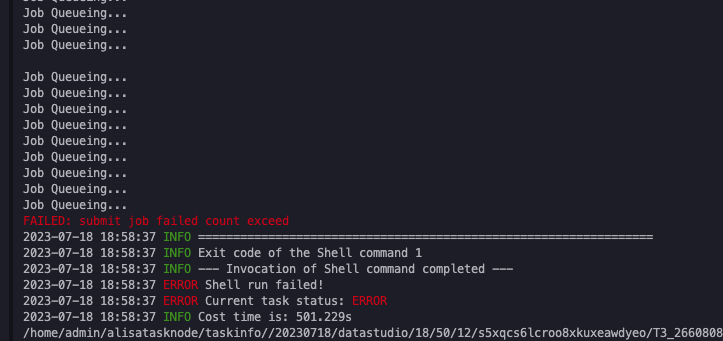
tongchenkeji 发表于:2023-7-25 17:31:410次点击 已关注取消关注 关注 私信 大数据计算MaxCompute目测pk表合并有点难度,合并小文件,一直 在查询?[阿里云MaxCompute] 暂停朗读为您朗读 大数据计算MaxCompute目测pk表合并有点难度,合并小文件,一直 在查询?时间长了就报错了 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 MaxCompute# MaxCompute2748# 云原生大数据计算服务 MaxCompute3255# 分布式计算2827# 大数据1264
算精通AM 2023-11-27 18:04:49 1 在阿里云的大数据计算 MaxCompute 产品中,当数据量较大时,可能会出现小文件过多或者数据分散的情况,导致数据查询和分析效率低下。为了解决这个问题,可以考虑使用 PK 表合并技术,将小文件合并成大文件,以提高数据查询和分析的效率。 PK 表合并是一种常见的数据合并技术,它通过将多个小文件按照某个主键字段进行合并,生成一个包含所有数据的大文件,以减少小文件数量和提高数据查询和分析效率。在 MaxCompute 中,可以使用 INSERT OVERWRITE 语句来实现 PK 表合并,例如: CopyINSERT OVERWRITE TABLE target_tableSELECT *FROM source_tableDISTRIBUTE BY SORT BY 上述示例中,我们使用了 INSERT OVERWRITE 语句来将 source_table 中的数据按照 pk_column 列的值进行合并,并将结果写入 target_table 中。同时,我们使用了 DISTRIBUTE BY 和 SORT BY 子句来指定数据的分布和排序方式,以提高合并效率和性能。
Star时光AM 2023-11-27 18:04:49 2 在大数据计算MaxCompute中,对PK表进行小文件合并可以是一项复杂而耗费资源的任务。如果您正在尝试合并小文件,但遇到了困难或查询的问题,请考虑以下几点: 合并策略:确保使用正确的合并策略。根据具体情况和需求,可以选择使用Tunnel工具或INSERT OVERWRITE TABLE语句来实现小文件的合并。 数据规模和资源:小文件合并可能需要处理大量的数据,并消耗较多的计算资源和存储空间。请确保您的集群资源足够,并且有足够的时间和计算能力来完成合并操作。 查询影响:合并过程中的查询操作可能会受到一定的性能影响。如果对查询性能有较高要求,可以考虑在非生产环境进行合并操作,以减少对生产环境的影响。 调优参数:您可以尝试调整MaxCompute的相关调优参数,例如调整tunnel.max.retry.count、tunnel.upload.session.file.count等参数,以优化合并过程中的性能和效率。 分批次合并:如果一次性合并所有小文件的操作非常困难或耗时较长,可以考虑将合并过程分批次进行,每次处理部分小文件。这样可以降低负载和资源消耗,并逐步完成合并任务。
在阿里云的大数据计算 MaxCompute 产品中,当数据量较大时,可能会出现小文件过多或者数据分散的情况,导致数据查询和分析效率低下。为了解决这个问题,可以考虑使用 PK 表合并技术,将小文件合并成大文件,以提高数据查询和分析的效率。
PK 表合并是一种常见的数据合并技术,它通过将多个小文件按照某个主键字段进行合并,生成一个包含所有数据的大文件,以减少小文件数量和提高数据查询和分析效率。在 MaxCompute 中,可以使用 INSERT OVERWRITE 语句来实现 PK 表合并,例如:
Copy
INSERT OVERWRITE TABLE target_table
SELECT *
FROM source_table
DISTRIBUTE BY
SORT BY
上述示例中,我们使用了 INSERT OVERWRITE 语句来将 source_table 中的数据按照 pk_column 列的值进行合并,并将结果写入 target_table 中。同时,我们使用了 DISTRIBUTE BY 和 SORT BY 子句来指定数据的分布和排序方式,以提高合并效率和性能。
在大数据计算MaxCompute中,对PK表进行小文件合并可以是一项复杂而耗费资源的任务。如果您正在尝试合并小文件,但遇到了困难或查询的问题,请考虑以下几点:
合并策略:确保使用正确的合并策略。根据具体情况和需求,可以选择使用Tunnel工具或INSERT OVERWRITE TABLE语句来实现小文件的合并。
数据规模和资源:小文件合并可能需要处理大量的数据,并消耗较多的计算资源和存储空间。请确保您的集群资源足够,并且有足够的时间和计算能力来完成合并操作。
查询影响:合并过程中的查询操作可能会受到一定的性能影响。如果对查询性能有较高要求,可以考虑在非生产环境进行合并操作,以减少对生产环境的影响。
调优参数:您可以尝试调整MaxCompute的相关调优参数,例如调整tunnel.max.retry.count、tunnel.upload.session.file.count等参数,以优化合并过程中的性能和效率。
分批次合并:如果一次性合并所有小文件的操作非常困难或耗时较长,可以考虑将合并过程分批次进行,每次处理部分小文件。这样可以降低负载和资源消耗,并逐步完成合并任务。