大数据计算MaxCompute可以进行标准差的计算吗?我最近研究了一下transaction 2.0表的小文件和存储,你可以作为参考。其实底层的存储逻辑应该不会透出的很细致,实际存储的话还是建议看收费明细。1. 首先我大概测试了一下合并transaction 2.0表的小文件,发现合并命令的运行日志中会打印出合并效果,比如起始file num=99,合并后为17;随机用desc extended命令看了下,file num=133,不减反增了。2. 这个情况我咨询了下研发,对于transaction 2.0表desc结果中的file num包含了历史版本的文件,因为transaction 2.0表 会对历史版本保留一段时间;而即使被合并的表小文件最终是多少,可以在合并日志中看到明细。所以结论:最新版本的按合并日志来看,普通全量查询只会查询到最新版本。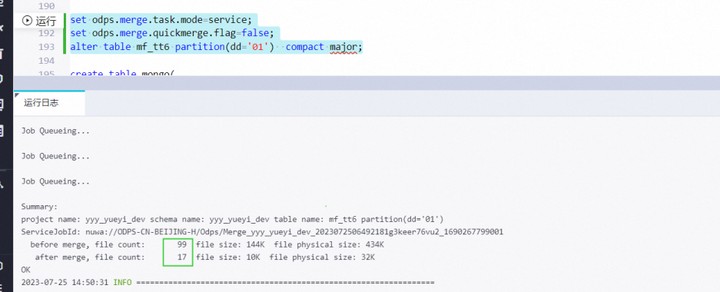
- 对于存储方面,我也发现了desc 结果中的存储量 比 合并日志中产生的存储量偏大,我理解这部分适合 2点逻辑一致,因为有不同版本的数据,所以存储量会偏大。而实际的存储计费,按照用量明细的账单来看最为准确;4. 有一点,如果在rention time 内做了多次major compaction的话,就会保留这么多大版本的数据,这个是有成本的,备份多的话,成本会高。详情可以看下这个文档:https://help.aliyun.com/zh/maxcompute/user-guide/timetravel-query-and-incremental-query?spm=a2c4g.11186623.0.0.39813addfWznpM
MaxCompute提供了统计函数来计算标准差。你可以使用
stddev函数来计算标准差。下面是一个示例:
在上述示例中,将
column_name替换为你要计算标准差的列名,your_table替换为你要进行计算的表名。关于你提到的Transaction 2.0表的小文件和存储情况,确实底层的存储逻辑不会直接透露给用户。根据你的描述,合并命令的运行日志会打印出合并效果,这可以作为参考来了解合并操作的影响。
同时,在Transaction 2.0表的
desc extended结果中,包含了历史版本的文件数量,因为Transaction 2.0表会保留一段时间的历史版本。而合并日志会显示被合并的小文件的详细信息。根据你的结论,普通全量查询只会查询到最新版本的数据,这与Transaction 2.0表的设计和工作原理相符。
请注意,MaxCompute的具体存储细节可能会因版本、配置和实际使用情况而有所不同。如果需要更详细的存储和收费明细,建议查看相关文档或联系MaxCompute提供商获取准确信息。
标准差看看STDDEV这个函数呢
https://help.aliyun.com/zh/maxcompute/user-guide/aggregate-functions?spm=a2c4g.11186623.0.i58#section-gg5-dv1-wdb,此回答整理自钉群“MaxCompute开发者社区2群”