tongchenkeji 发表于:2023-4-19 16:28:470次点击 已关注取消关注 关注 私信 Flink状态怎么有大有小?是为什么呢?[阿里云实时计算 Flink版] 暂停朗读为您朗读 Flink状态怎么有大有小? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 实时计算Flink版# 实时计算 Flink版3179# 流计算2236
wljslmzAM 2023-11-27 18:11:13 1 Flink 状态在运行中的大小,主要与两个因素有关系: 状态存储的数据量 在 Flink 任务运行过程中,需要存储一些状态数据,如键控状态、窗口状态等。这些状态数据的大小,取决于输入数据的内容、窗口大小等因素。如果输入数据的键非常多,那么状态数据也会非常大。 并行度 Flink 任务的状态大小还与任务的并行度有关。每个并行任务都会生成一份状态数据,因此并行度越高,状态数据也会相应增加。同时,对于 keyed state 而言,其状态大小还与 Key 的数量有关。如果多个 Key 的状态数据被分配到了同一个 Task Manager,那么它们就会被合并,从而导致状态数据变得更大。 因此,Flink 的状态大小是与具体的应用场景有关的,需要根据具体情况进行分析,并视情况进行调优。当在任务运行过程中出现状态数据过大,可以考虑通过以下方式进行优化: 调整窗口大小或窗口类型,减少状态数据存储量。 调整并行度或者调整 Key 的数量,减少状态数量,使同一个 Task Manager 分配到的 Key 数量不会太多。 使用 RocksDBStateBackend 或者 FsStateBackend 这类高效的状态后端,提高状态存储的效率。 调整用户代码,减少中间数据量,从而减少状态存储量。
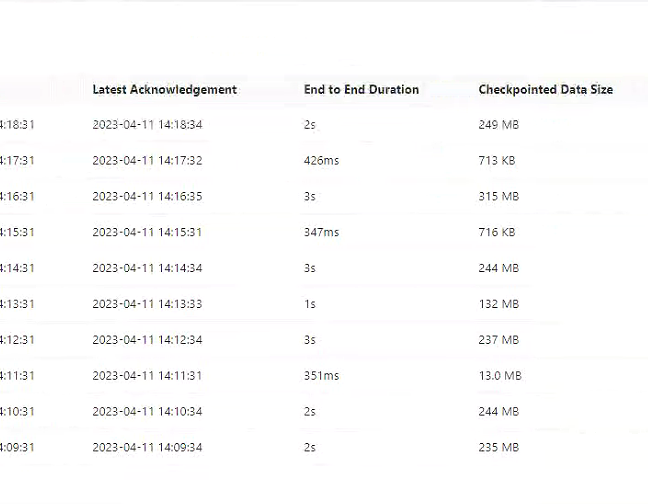
飞云觅宙AM 2023-11-27 18:11:13 2 在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。 在流处理过程中那些需要记住的数据,而这些数据既可以包括业务数据,也可以包括元数据。Flink 本身提供了不同的状态管理器来管理状态,并且这个状态可以非常大。 Flink状态有大有小,原因是使用中间表后因为中间数据也在作为sink输出,这样数据变化时会像一个传送带一样第一层数据变化引起第二层变化然后引起第三层变化。 解决方法:开启微批将中间数据跳动过滤掉,设置如下: table.exec.mini-batch.enabled 设置微true table.exec.mini-batch.allow-latency 缓存数据最大的时间间隔,超过该间隔,将会强制触发已聚合数据写出给下游,默认-1毫秒即立即触发,可以根据需求自行调整。实时性要求较高可以适当调低,实时性要求不高可调高 table.exec.mini-batch.size 黄村数据量最大条数,为防止oom做的双重保障与table.exec.mini-batch.allow-latency设置的时间满足一个就会触发。
 Flink状态怎么有大有小? Flink状态怎么有大有小?
Flink状态怎么有大有小? Flink状态怎么有大有小?
Flink 状态在运行中的大小,主要与两个因素有关系:
在 Flink 任务运行过程中,需要存储一些状态数据,如键控状态、窗口状态等。这些状态数据的大小,取决于输入数据的内容、窗口大小等因素。如果输入数据的键非常多,那么状态数据也会非常大。
Flink 任务的状态大小还与任务的并行度有关。每个并行任务都会生成一份状态数据,因此并行度越高,状态数据也会相应增加。同时,对于 keyed state 而言,其状态大小还与 Key 的数量有关。如果多个 Key 的状态数据被分配到了同一个 Task Manager,那么它们就会被合并,从而导致状态数据变得更大。
因此,Flink 的状态大小是与具体的应用场景有关的,需要根据具体情况进行分析,并视情况进行调优。当在任务运行过程中出现状态数据过大,可以考虑通过以下方式进行优化:
调整窗口大小或窗口类型,减少状态数据存储量。
调整并行度或者调整 Key 的数量,减少状态数量,使同一个 Task Manager 分配到的 Key 数量不会太多。
使用 RocksDBStateBackend 或者 FsStateBackend 这类高效的状态后端,提高状态存储的效率。
调整用户代码,减少中间数据量,从而减少状态存储量。
在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。
在流处理过程中那些需要记住的数据,而这些数据既可以包括业务数据,也可以包括元数据。Flink 本身提供了不同的状态管理器来管理状态,并且这个状态可以非常大。
Flink状态有大有小,原因是使用中间表后因为中间数据也在作为sink输出,这样数据变化时会像一个传送带一样第一层数据变化引起第二层变化然后引起第三层变化。
解决方法:开启微批将中间数据跳动过滤掉,设置如下: table.exec.mini-batch.enabled 设置微true table.exec.mini-batch.allow-latency 缓存数据最大的时间间隔,超过该间隔,将会强制触发已聚合数据写出给下游,默认-1毫秒即立即触发,可以根据需求自行调整。实时性要求较高可以适当调低,实时性要求不高可调高 table.exec.mini-batch.size 黄村数据量最大条数,为防止oom做的双重保障与table.exec.mini-batch.allow-latency设置的时间满足一个就会触发。