tongchenkeji 发表于:2023-7-13 10:20:560次点击 已关注取消关注 关注 私信 请问一下,写FlinkKafkaProducer自定义实现Partitioner,一直报这样的问题?[阿里云实时计算 Flink版] 暂停朗读为您朗读 请问一下,写FlinkKafkaProducer自定义实现Partitioner,一直报这样的问题是什么原因? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 实时计算Flink版# 云消息队列 Kafka 版375# 实时计算 Flink版3179
算精通AM 2023-11-27 18:13:21 1 在 Flink 中使用 FlinkKafkaProducer 自定义实现 Partitioner,需要实现 KafkaPartitioner 接口,并在 FlinkKafkaProducer 中使用 setFlinkKafkaPartitioner() 方法设置自定义的 Partitioner。出现问题可能是因为自定义的 Partitioner 实现不正确或者在设置 Partitioner 时出现错误。 具体而言,如果您在使用自定义的 Partitioner 时出现问题,可以考虑以下几个方面: Partitioner 实现不正确:自定义的 Partitioner 需要正确实现 KafkaPartitioner 接口,并根据业务需求实现自定义的分区逻辑。可以检查一下 Partitioner 实现的代码,确保代码逻辑正确、参数传递正确等。 Partitioner 配置不正确:在使用 FlinkKafkaProducer 设置 Partitioner 时,需要使用 setFlinkKafkaPartitioner() 方法,并传递自定义的 Partitioner 实例。可以检查一下 Partitioner 的配置是否正确、是否传递了正确的参数等。 序列化问题:如果自定义的 Partitioner 中使用了自定义的类或者对象,需要确保这些类或者对象可以被序列化和反序列化。可以检查一下自定义的类或者对象是否实现了 Serializable 接口,并且是否能够被正确序列化和反序列化。
Star时光AM 2023-11-27 18:13:21 2 以下几个方面可能导致报错: 1. 类型不匹配:确保您的自定义 Partitioner 实现正确继承了 org.apache.flink.streaming.connectors.kafka.partitioner.FlinkKafkaPartitioner 接口,并正确重写了其中的方法。 2. 序列化问题:检查您的自定义 Partitioner 类是否可序列化。Flink 在分布式环境中需要对类进行序列化和反序列化。如果您的自定义 Partitioner 类没有正确实现 Serializable 接口或使用了不支持序列化的对象,可能会导致报错。 3. 参数配置错误:确保将自定义 Partitioner 配置到 FlinkKafkaProducer 时,参数设置正确。例如,通过 setCustomPartitioner() 方法将自定义 Partitioner 设置给 FlinkKafkaProducer,并确保传递正确的参数。 4. 引入依赖问题:如果自定义 Partitioner 使用了其他库或依赖,请确保这些依赖已通过适当的方式引入到您的项目中。可能需要检查版本兼容性以及包冲突等问题。 请尽量提供更多的报错信息或相关代码片段,这样可以帮助我们更准确地定位问题并给出解决方案。另外,也建议您查看 Flink 的日志文件,其中可能包含更详细的错误信息。
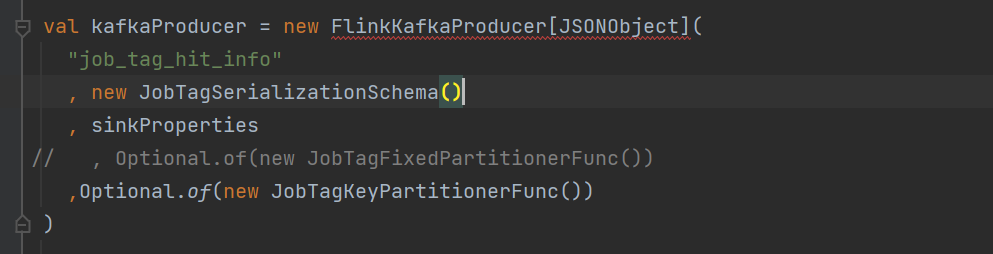
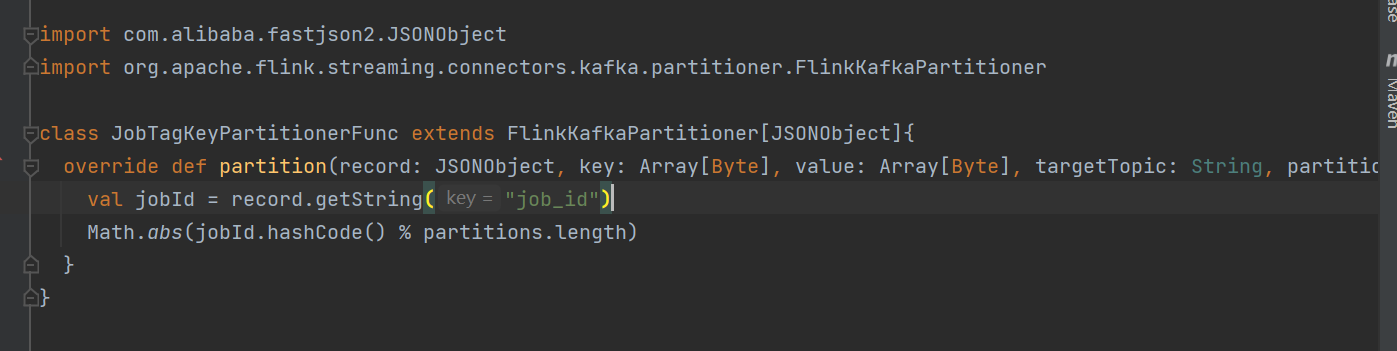
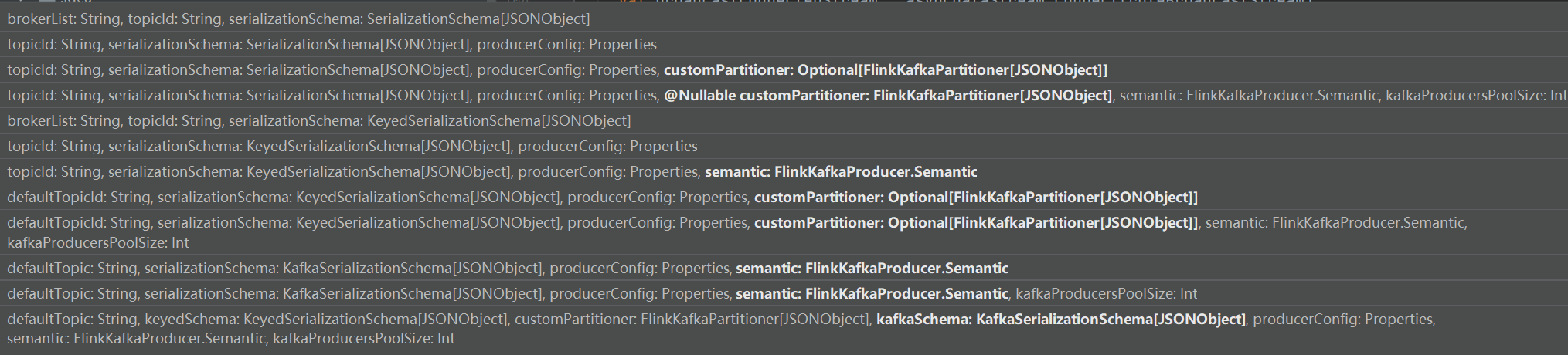
在 Flink 中使用 FlinkKafkaProducer 自定义实现 Partitioner,需要实现 KafkaPartitioner 接口,并在 FlinkKafkaProducer 中使用 setFlinkKafkaPartitioner() 方法设置自定义的 Partitioner。出现问题可能是因为自定义的 Partitioner 实现不正确或者在设置 Partitioner 时出现错误。
具体而言,如果您在使用自定义的 Partitioner 时出现问题,可以考虑以下几个方面:
Partitioner 实现不正确:自定义的 Partitioner 需要正确实现 KafkaPartitioner 接口,并根据业务需求实现自定义的分区逻辑。可以检查一下 Partitioner 实现的代码,确保代码逻辑正确、参数传递正确等。
Partitioner 配置不正确:在使用 FlinkKafkaProducer 设置 Partitioner 时,需要使用 setFlinkKafkaPartitioner() 方法,并传递自定义的 Partitioner 实例。可以检查一下 Partitioner 的配置是否正确、是否传递了正确的参数等。
序列化问题:如果自定义的 Partitioner 中使用了自定义的类或者对象,需要确保这些类或者对象可以被序列化和反序列化。可以检查一下自定义的类或者对象是否实现了 Serializable 接口,并且是否能够被正确序列化和反序列化。
以下几个方面可能导致报错:
1. 类型不匹配:确保您的自定义 Partitioner 实现正确继承了
org.apache.flink.streaming.connectors.kafka.partitioner.FlinkKafkaPartitioner接口,并正确重写了其中的方法。2. 序列化问题:检查您的自定义 Partitioner 类是否可序列化。Flink 在分布式环境中需要对类进行序列化和反序列化。如果您的自定义 Partitioner 类没有正确实现 Serializable 接口或使用了不支持序列化的对象,可能会导致报错。
3. 参数配置错误:确保将自定义 Partitioner 配置到 FlinkKafkaProducer 时,参数设置正确。例如,通过
setCustomPartitioner()方法将自定义 Partitioner 设置给 FlinkKafkaProducer,并确保传递正确的参数。4. 引入依赖问题:如果自定义 Partitioner 使用了其他库或依赖,请确保这些依赖已通过适当的方式引入到您的项目中。可能需要检查版本兼容性以及包冲突等问题。
请尽量提供更多的报错信息或相关代码片段,这样可以帮助我们更准确地定位问题并给出解决方案。另外,也建议您查看 Flink 的日志文件,其中可能包含更详细的错误信息。