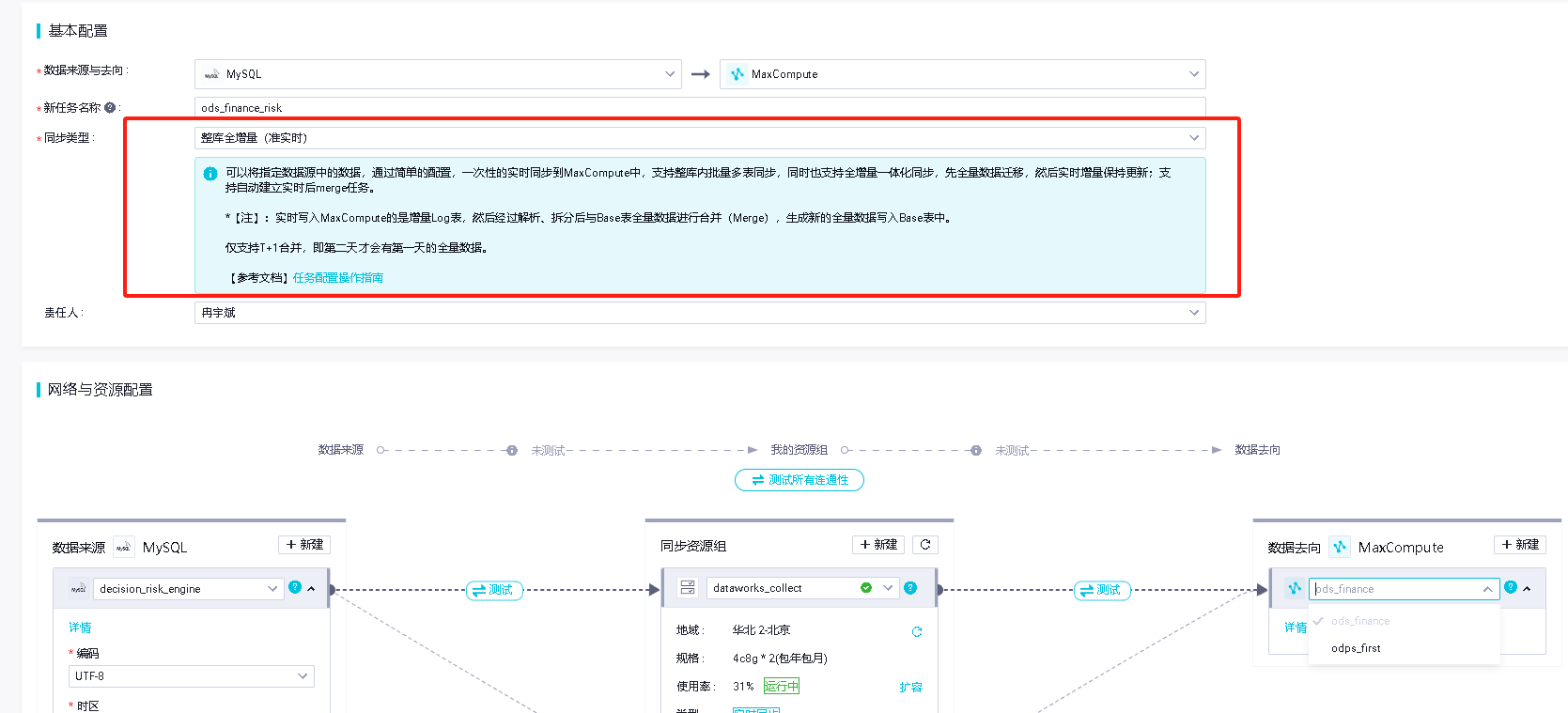
tongchenkeji 发表于:2023-10-22 21:11:010次点击 已关注取消关注 关注 私信 DataWorks读取的是MySQL中的数据还是读取的bingLog啊?[阿里云MaxCompute] 暂停朗读为您朗读 DataWorks数据集成从MySQL至maxCompute使用整库全增量(准实时),读取的是MySQL中的数据还是读取的bingLog啊? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 MaxCompute# DataWorks3343# MaxCompute2748# MySQL1179# 关系型数据库2577# 分布式计算2827# 大数据开发治理平台 DataWorks3946# 数据集成 Data Integration293
sun20AM 2023-11-27 18:17:23 1 在阿里云的DataWorks中,数据集成从MySQL至MaxCompute使用整库全增量(准实时)时,它并不是直接读取MySQL中的数据,而是读取MySQL的binlog。 这种模式的工作原理是,数据集成任务会定期从MySQL中抓取最新的binlog,然后解析binlog中的事件,提取出数据,然后将数据写入MaxCompute。这种方式可以实现实时的数据同步,但是需要MySQL支持binlog,并且需要保证binlog的完整性和一致性。 这种方式并不能保证数据的绝对实时性,因为数据集成任务可能会因为各种原因(如网络问题、系统故障等)而中断,导致数据无法及时同步。
小周sirAM 2023-11-27 18:17:23 2 在DataWorks中,从MySQL至MaxCompute使用整库全增量(准实时)的数据集成方式,读取的是MySQL中的数据。这种方式通过在MySQL数据库上设置binlog日志,将MySQL中的数据变更实时记录到binlog中。然后在DataWorks中,通过读取MySQL的binlog日志,将MySQL中的数据变更实时同步到MaxCompute中。这种方式的优点是可以实现数据的实时同步,缺点是需要在MySQL上设置binlog日志,并且需要消耗一定的系统资源。同时,由于MySQL和MaxCompute的数据类型和存储方式可能不同,因此在进行数据同步时,可能需要进行一定的数据转换和格式化。因此,您需要根据您的实际需求和环境,选择合适的数据集成方式。
在阿里云的DataWorks中,数据集成从MySQL至MaxCompute使用整库全增量(准实时)时,它并不是直接读取MySQL中的数据,而是读取MySQL的binlog。
这种模式的工作原理是,数据集成任务会定期从MySQL中抓取最新的binlog,然后解析binlog中的事件,提取出数据,然后将数据写入MaxCompute。这种方式可以实现实时的数据同步,但是需要MySQL支持binlog,并且需要保证binlog的完整性和一致性。
这种方式并不能保证数据的绝对实时性,因为数据集成任务可能会因为各种原因(如网络问题、系统故障等)而中断,导致数据无法及时同步。
在DataWorks中,从MySQL至MaxCompute使用整库全增量(准实时)的数据集成方式,读取的是MySQL中的数据。这种方式通过在MySQL数据库上设置binlog日志,将MySQL中的数据变更实时记录到binlog中。然后在DataWorks中,通过读取MySQL的binlog日志,将MySQL中的数据变更实时同步到MaxCompute中。
这种方式的优点是可以实现数据的实时同步,缺点是需要在MySQL上设置binlog日志,并且需要消耗一定的系统资源。同时,由于MySQL和MaxCompute的数据类型和存储方式可能不同,因此在进行数据同步时,可能需要进行一定的数据转换和格式化。
因此,您需要根据您的实际需求和环境,选择合适的数据集成方式。