问题1:大家好,Flink中有个pemja 的使用问题想请教各位一下。
需求是 java 通过pemja 来执行 python
目前发现以下问题,单次执行,数据量为10M,执行很快
但是在并发情况下,执行效率偏低?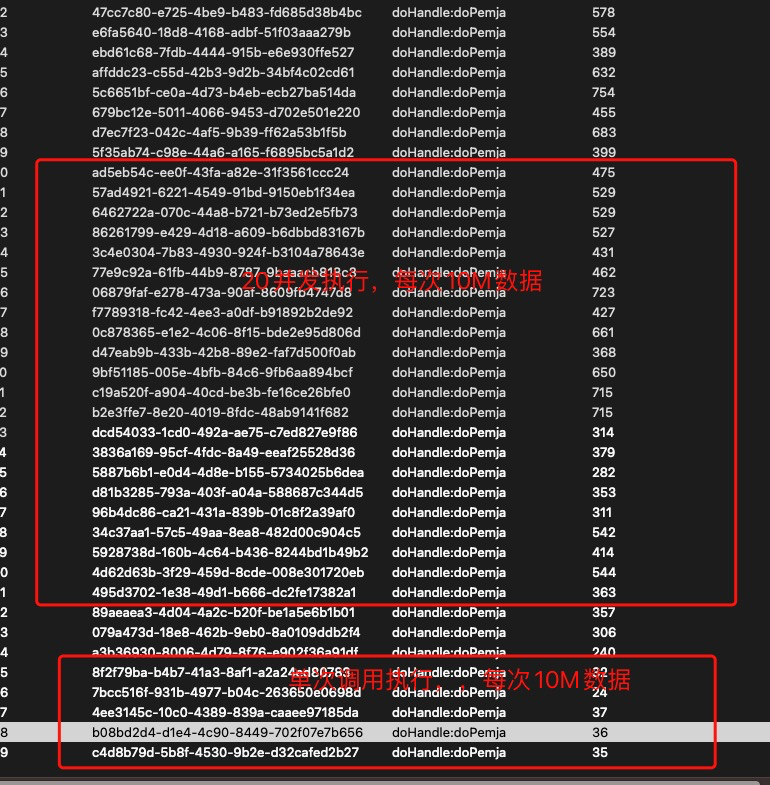


这是 config配置,采用的多线程模式,慢的点就是在调用执行器的几个方法的时候,这几个方法底层方法是有锁的么?单次就是 当前只有一次通过pemja执行python的任务
并发就是 同时有好几个通过pemja执行python脚本的任务
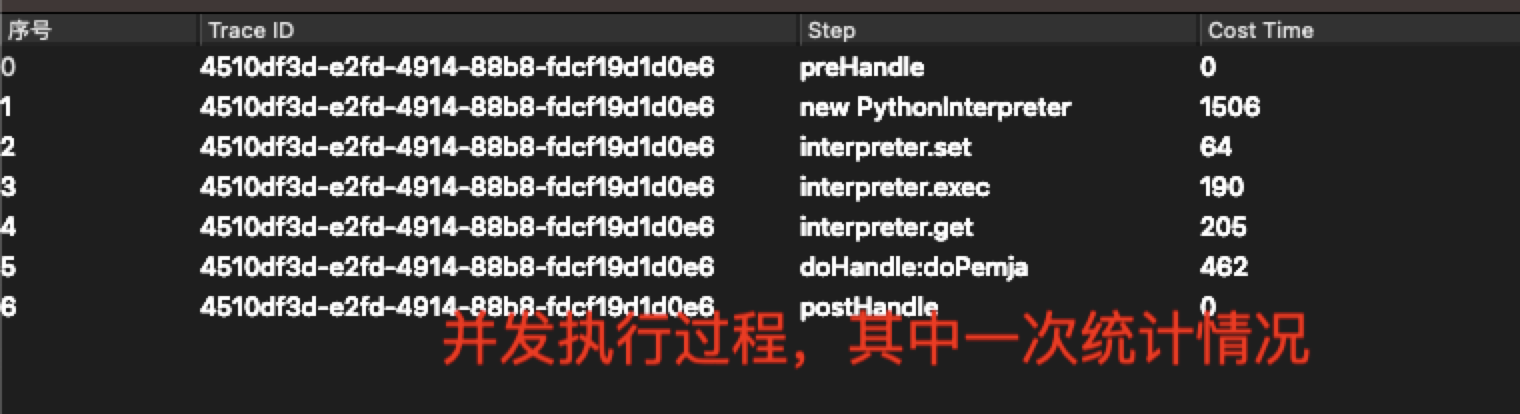
源码我看new PythonInterpreter是加锁了的
那请问 interpreter.exec,interpreter.invoke 这些native方法是否也是加锁的
因为我发现并发执行的时候 interpreter.exec,interpreter.invoke这几个方法执行感觉也是有锁一样
问题2:也就是说这个只能串行的方式执行python 脚本?
使用 Flink 中的 PEMJA(Parallel Execution of Multiple Java Applications)功能。PEMJA 是 Flink 的一个实验性功能,可以在同一个 Flink 集群中并行执行多个 Java 应用程序,从而提高资源利用率和任务吞吐量。
如果您需要在 Flink 中使用 PEMJA,可以按照以下步骤进行操作:
在 Flink 集群中启用 PEMJA
要使用 PEMJA 功能,需要在 Flink 集群的配置文件中启用 PEMJA。具体来说,在 flink-conf.yaml 文件中添加以下配置信息:
stylus
Copy
parallelism.default: 1
parallelism.max: 2
pemja.enabled: true
pemja.num.apps: 2
pemja.app.0.jars: /path/to/app1.jar
pemja.app.0.args: arg1 arg2
pemja.app.1.jars: /path/to/app2.jar
pemja.app.1.args: arg1 arg2
在上面的配置中,parallelism.default 和 parallelism.max 分别表示默认并行度和最大并行度,pemja.enabled 表示是否启用 PEMJA 功能,pemja.num.apps 表示要并行执行的应用程序数量,pemja.app.X.jars 表示应用程序 X 的 JAR 文件路径,pemja.app.X.args 表示应用程序 X 的启动参数。
编写应用程序
编写符合 PEMJA 要求的应用程序。具体来说,应用程序需要实现 main() 方法,并使用 PEMJA 提供的 API 来进行初始化和启动。例如,下面是一个 PEMJA 应用程序的简单示例:
java
Copy
public class MyPEMJAApp {
public static void main(String[] args) throws Exception { PEMJAApplication app = new PEMJAApplication(); app.setEntryPointClassName(MyPEMJAEntryPoint.class.getName()); app.setEntryPointMethodName("main"); app.setParallelism(2); app.run(args);}}
在这个示例中,MyPEMJAApp 类是 PEMJA 应用程序的入口类,通过 PEMJA 提供的 PEMJAApplication 类来初始化和启动应用程序。其中,
问题1:您在并发情况下使用 pemja 执行 Python 脚本时遇到了效率低下的问题。根据您提供的信息,我了解到您正在使用多线程模式,并且观察到在调用执行器的几个方法时性能较慢。您想知道这些底层方法是否有锁。
根据您提供的截图,Flink 中的 pemja 是通过 Jython 实现的,而 Jython 则是将 Python 代码转换为 Java 字节码来执行的。在 Jython 的实现中,确实会使用一些锁来保证线程安全性。
关于
interpreter.exec和interpreter.invoke这两个方法,在源码中确实使用了锁来实现线程同步。因此,在并发情况下,多个任务同时执行这些方法可能会受到锁的竞争影响,导致性能下降。问题2:基于上述情况,可以得出结论,Jython 在执行 Python 脚本时是以串行方式执行的。由于使用了锁进行线程同步,多个任务同时执行 Python 代码时会受到性能影响,无法充分利用多线程并发的优势。
如果您有高并发的需求,并且希望在 Flink 中执行 Python 脚本,您可以考虑以下方案:
– 将 Python 脚本拆分为多个独立任务,并使用更细粒度的并行度(parallelism)来提高任务的并发性。 – 考虑使用其他支持多线程或异步执行的 Python 运行时,例如 PySpark 中的 Py4j 或使用 Python 自身提供的并发库来实现并发执行。
需要注意的是,在处理大量数据时,Python 的全局解释器锁(GIL)可能会限制多线程并行执行的效果。因此,如果您的主要目标是通过并发执行提高处理速度,您可能需要考虑使用其他更适合并行计算的工具或框架,如 PySpark、Dask 等。
回答1:你的单次和并发的区别是啥?只是这两种模式不同吗?
对了 这玩意默认情况下就是 多线程 那个type 加和不加没有区别,此回答整理自钉群“【③群】Apache Flink China社区”